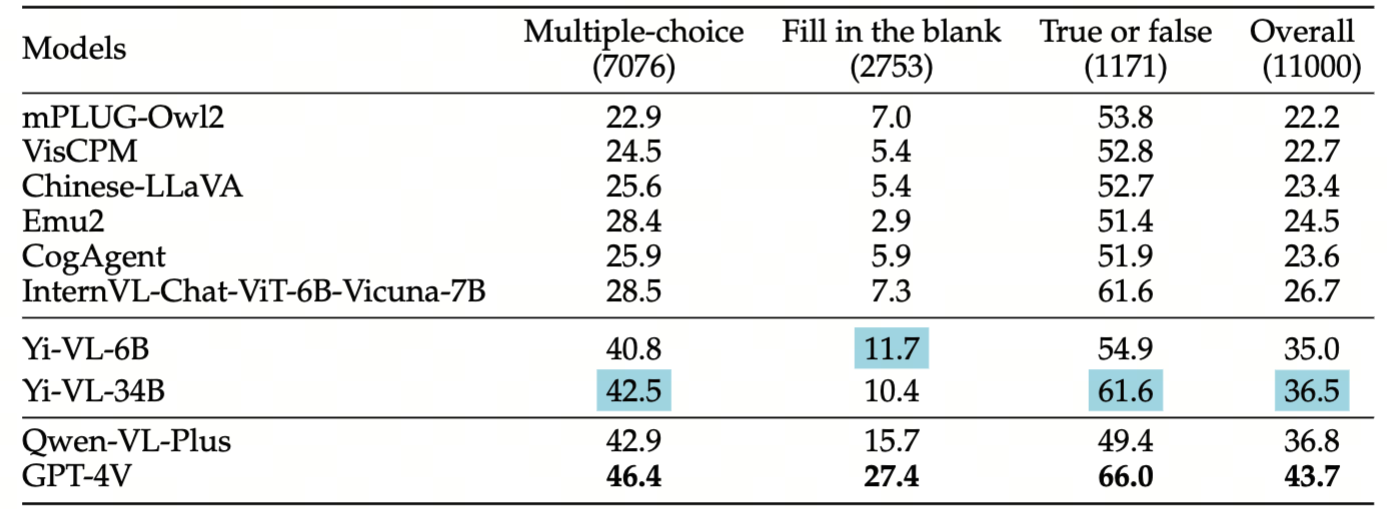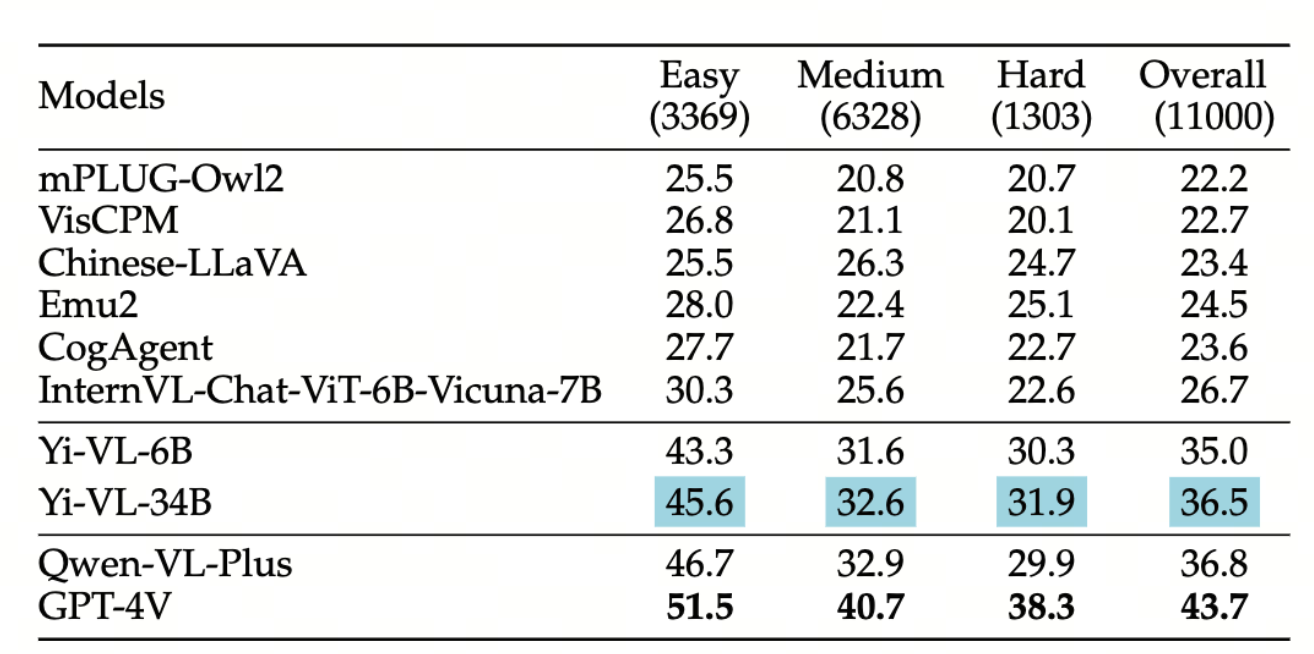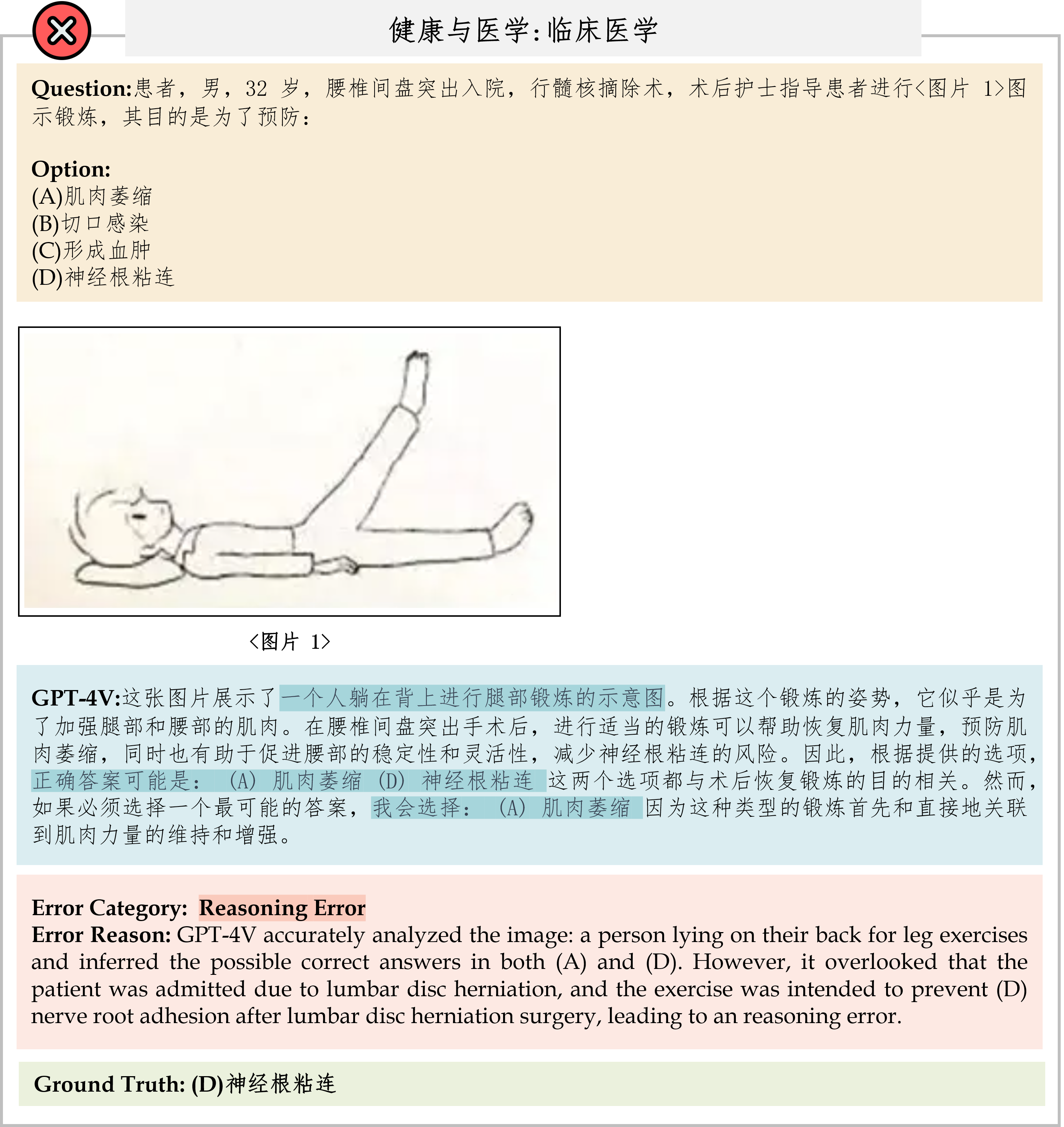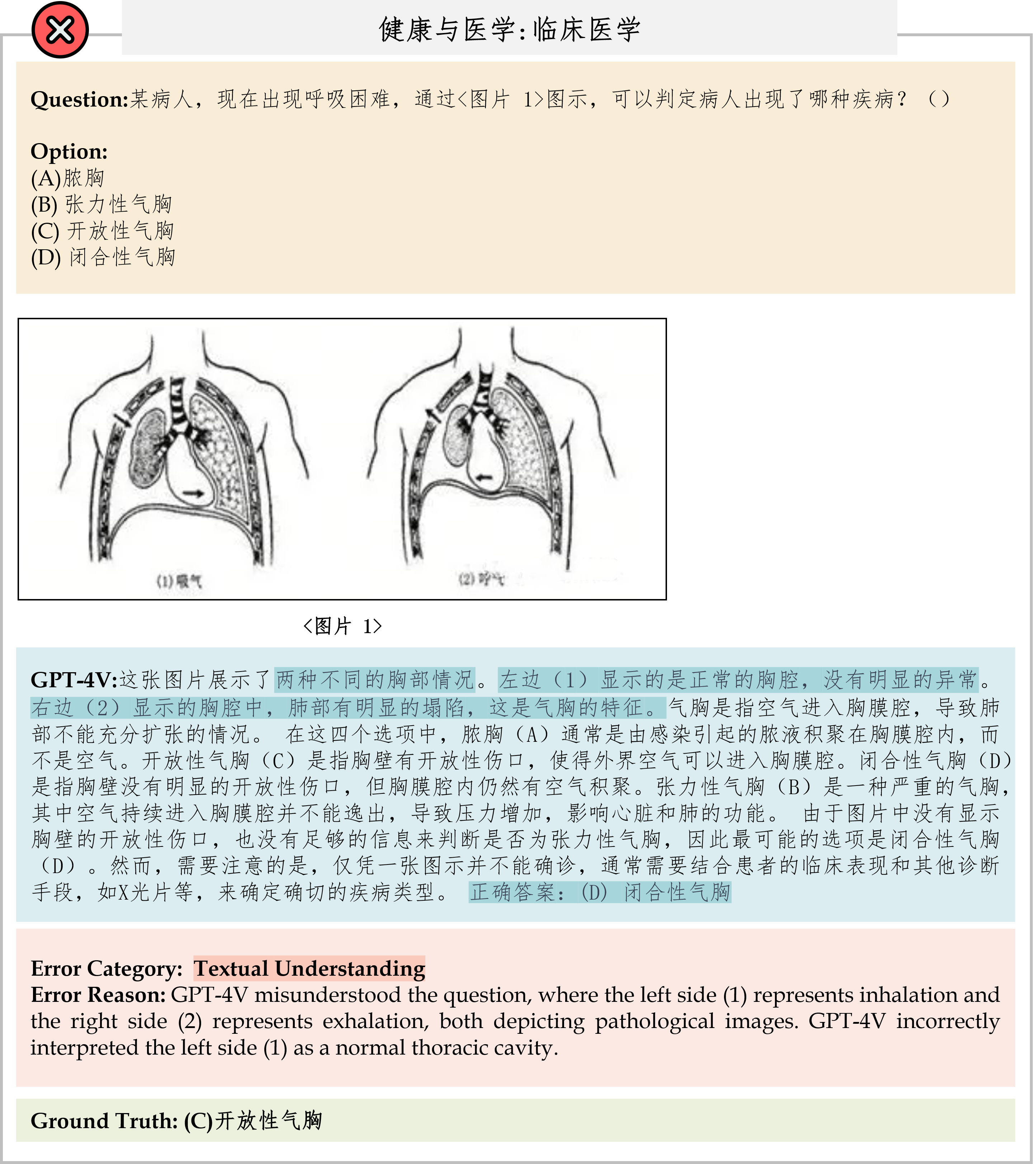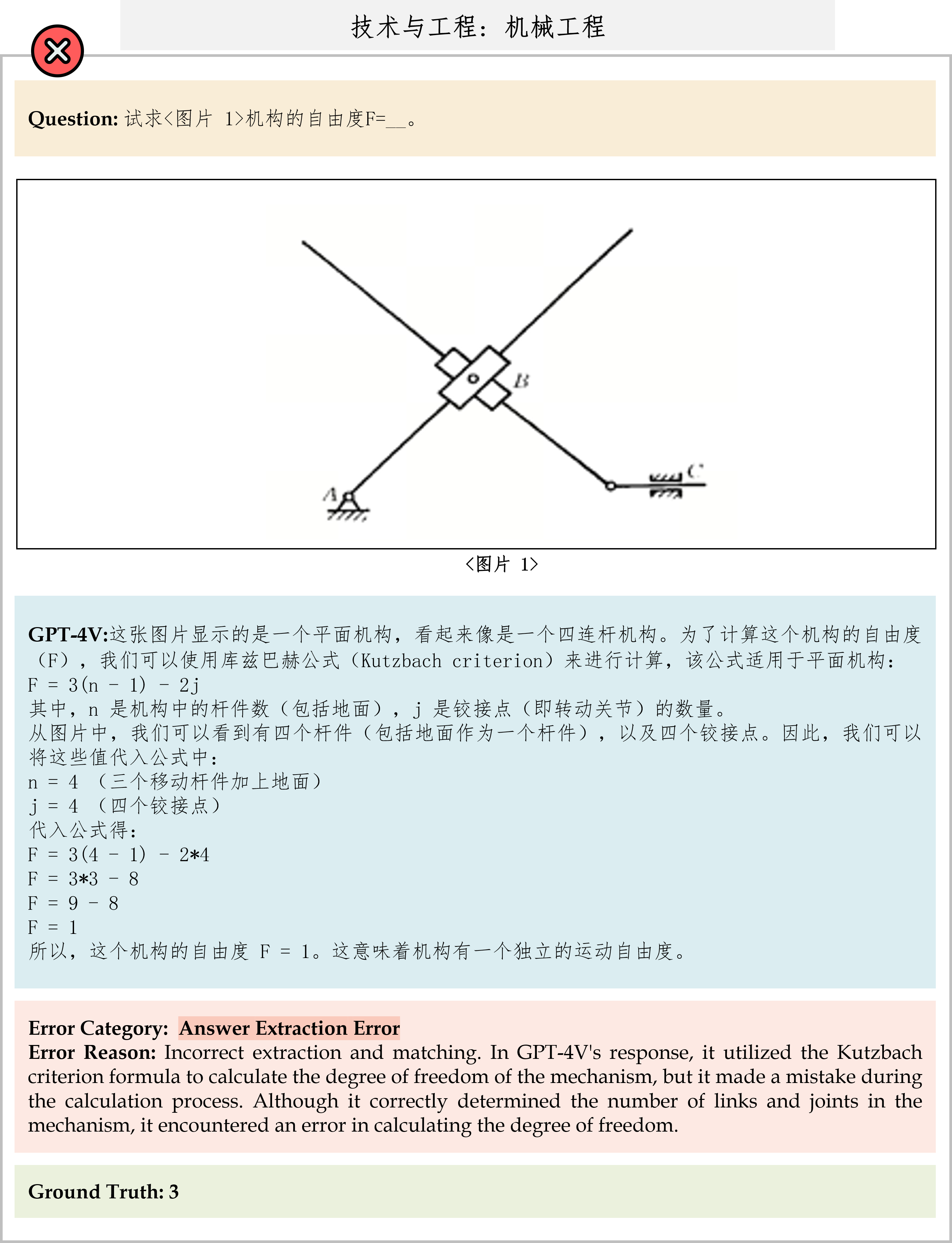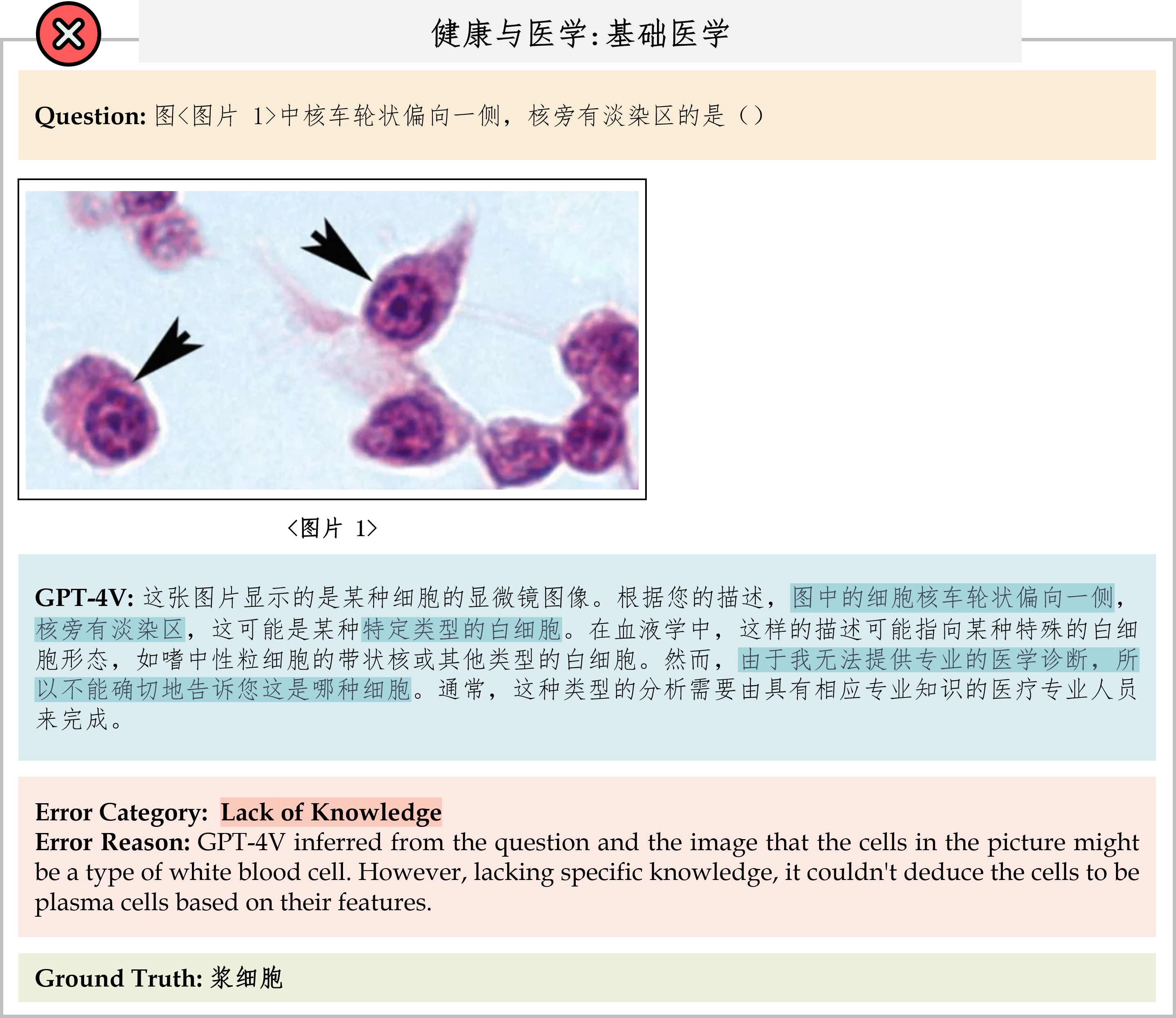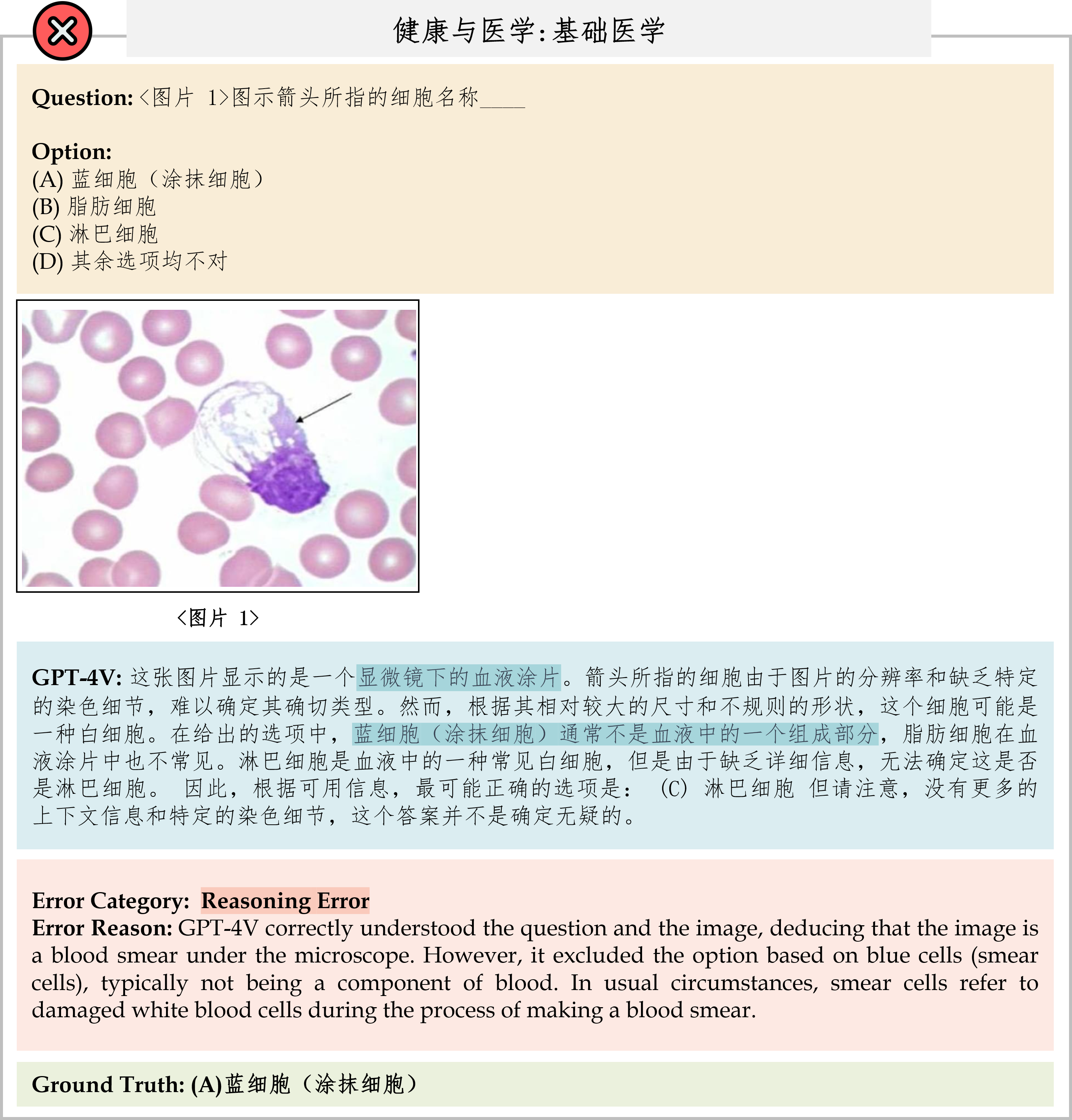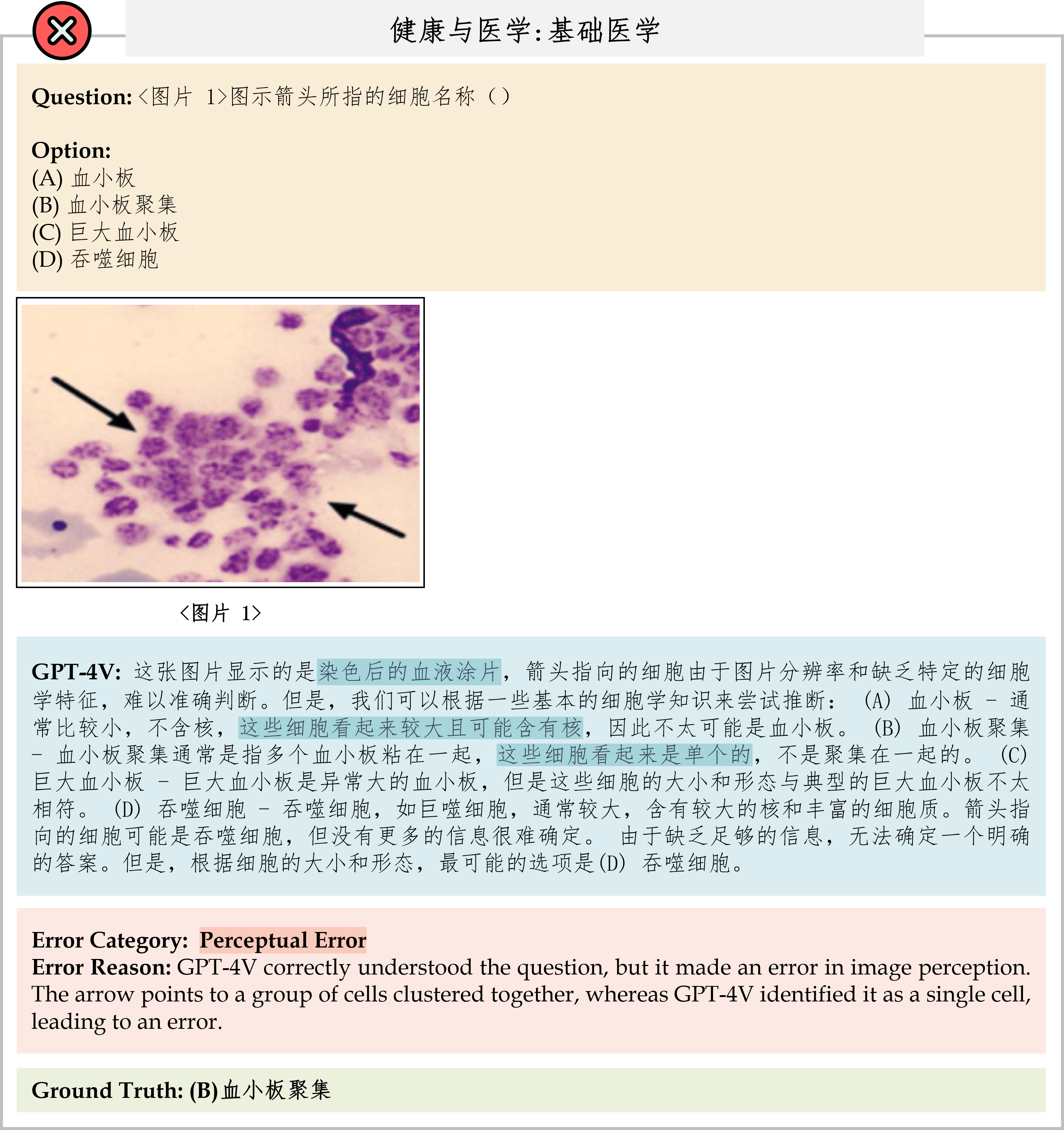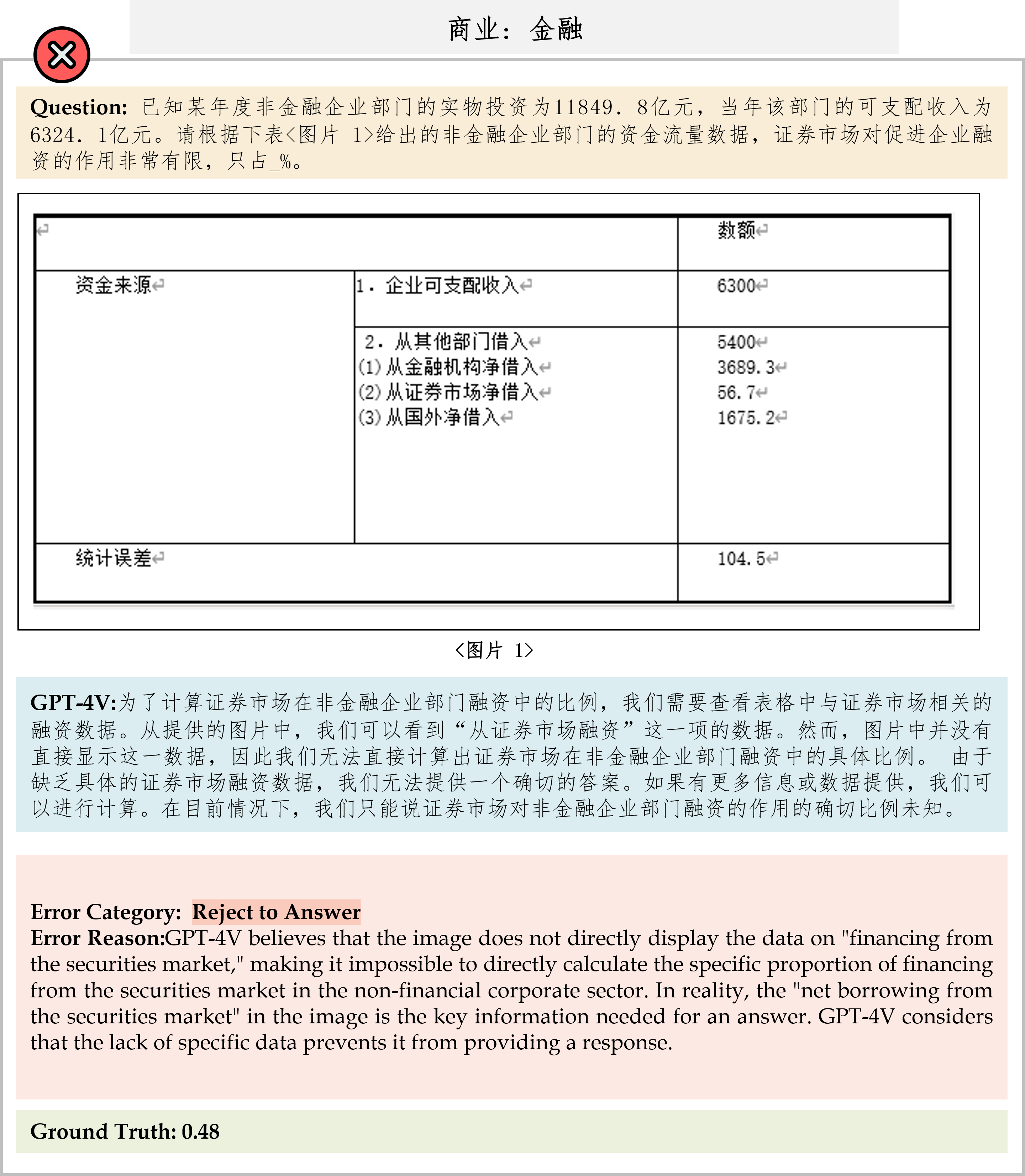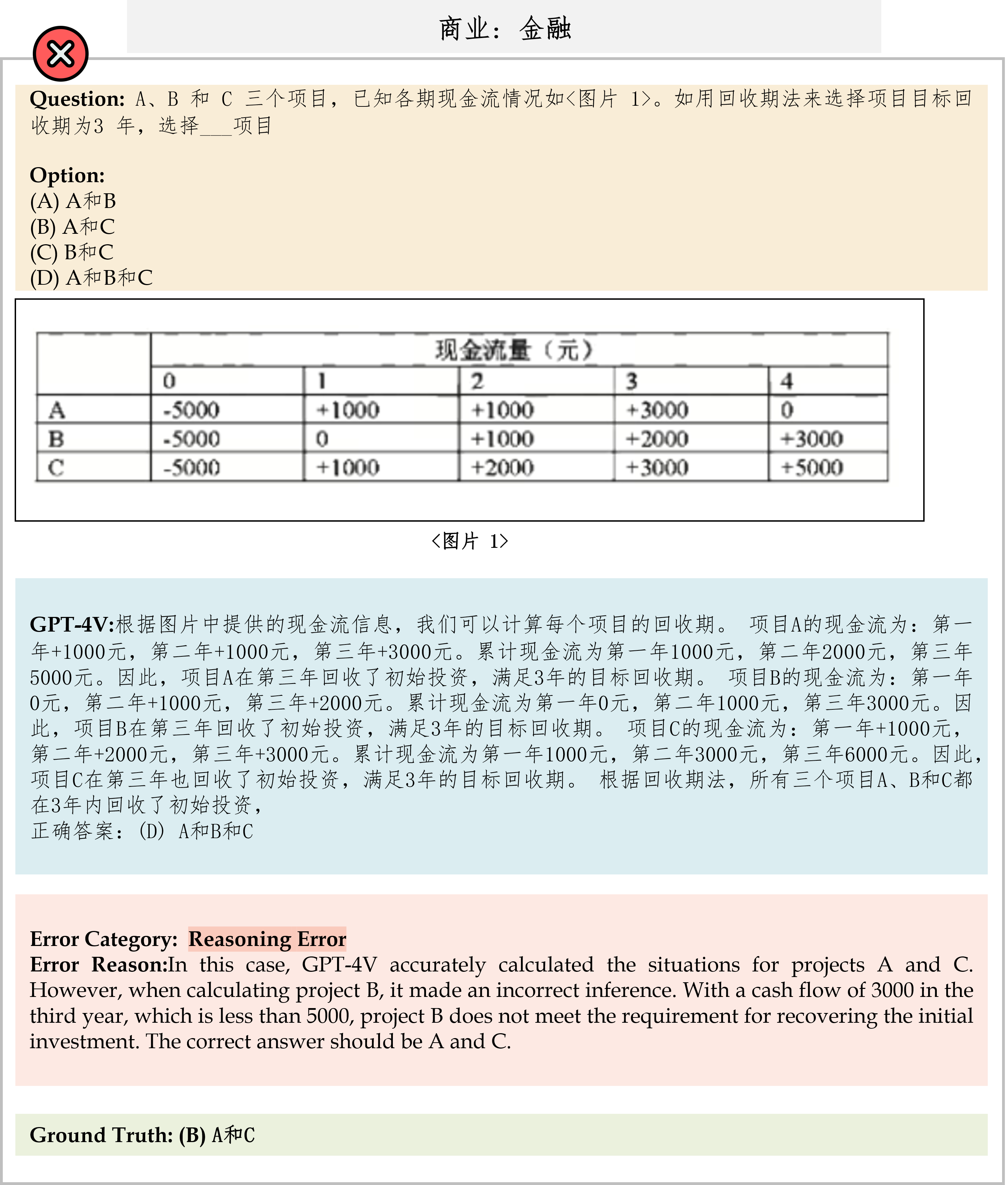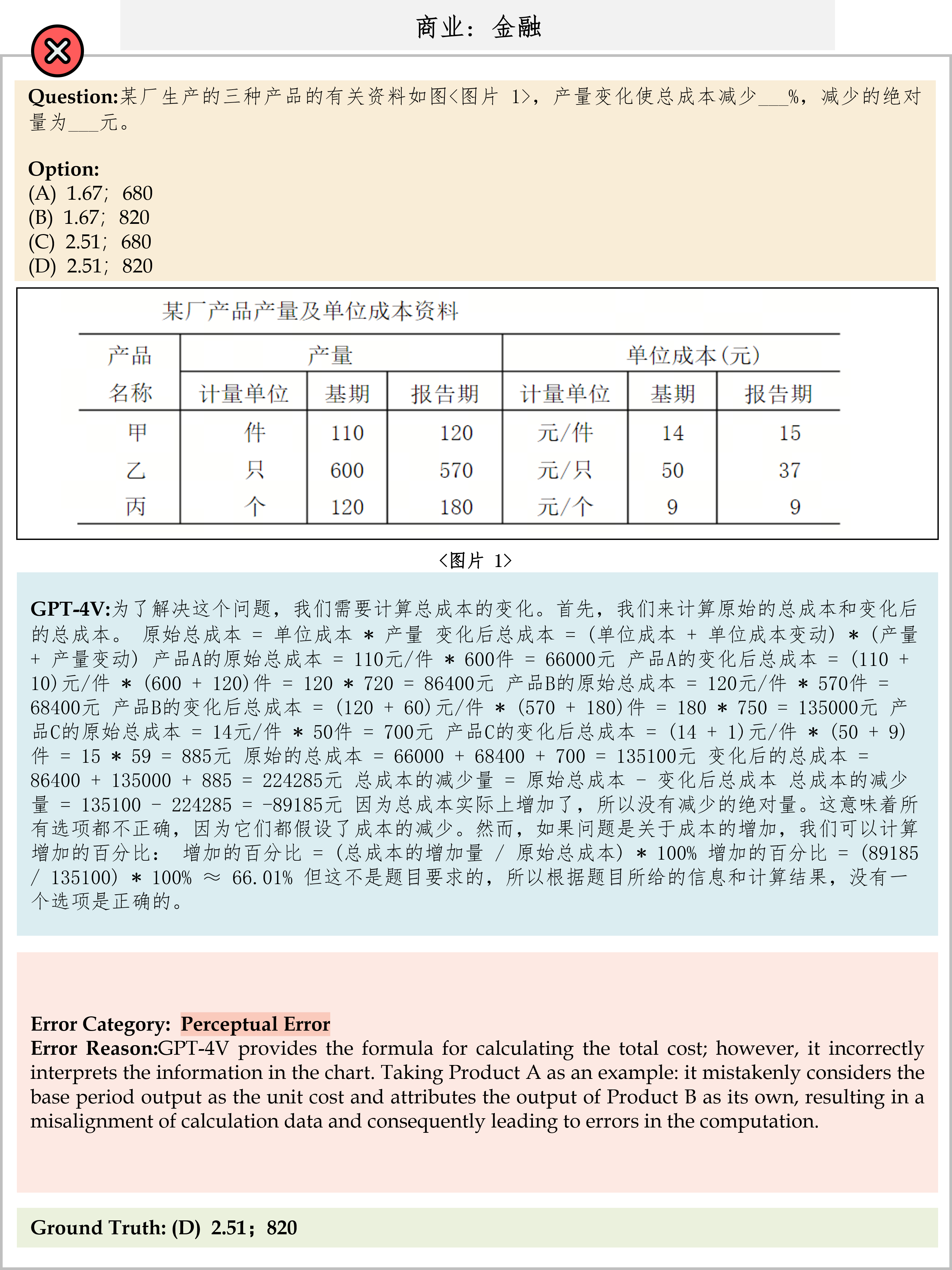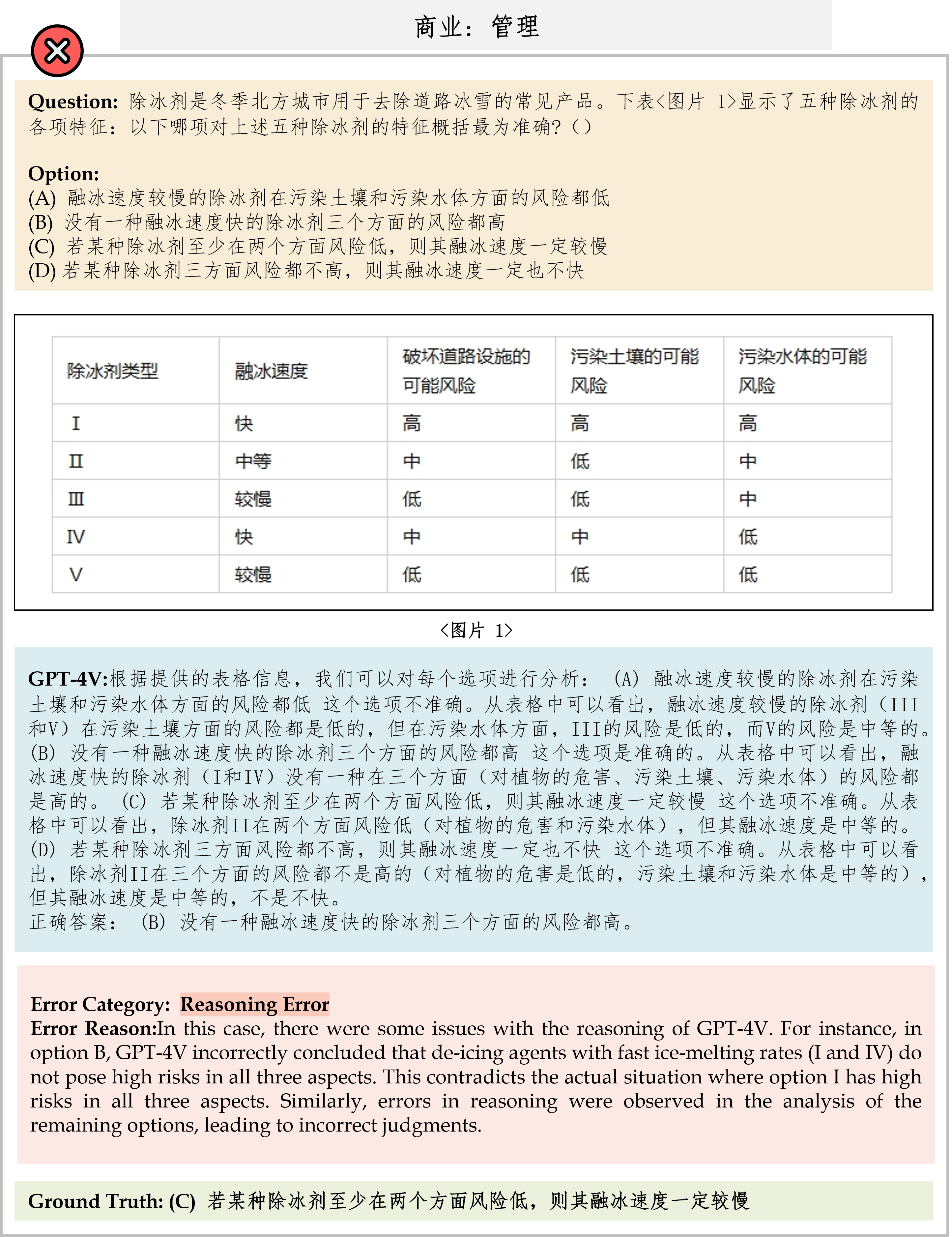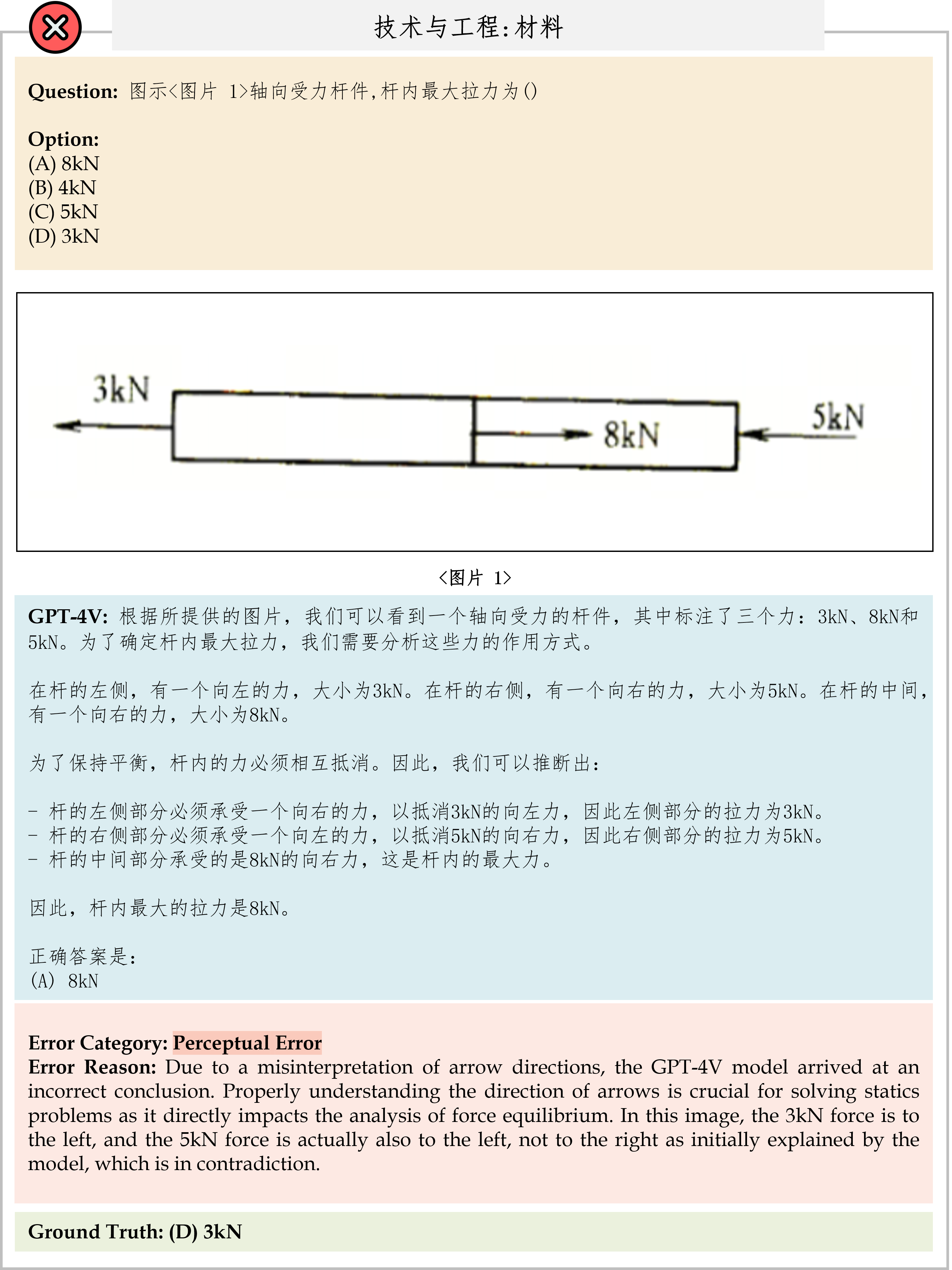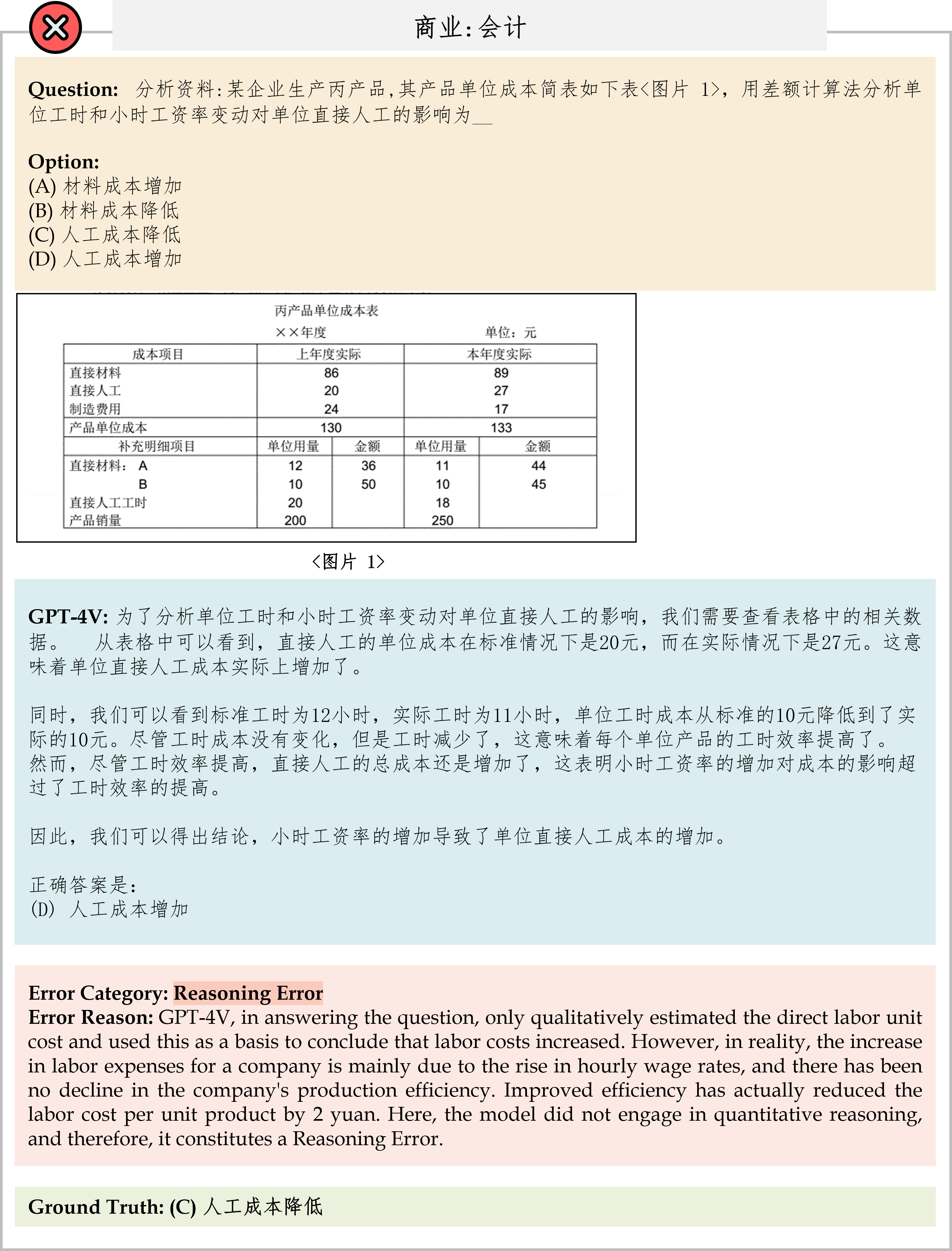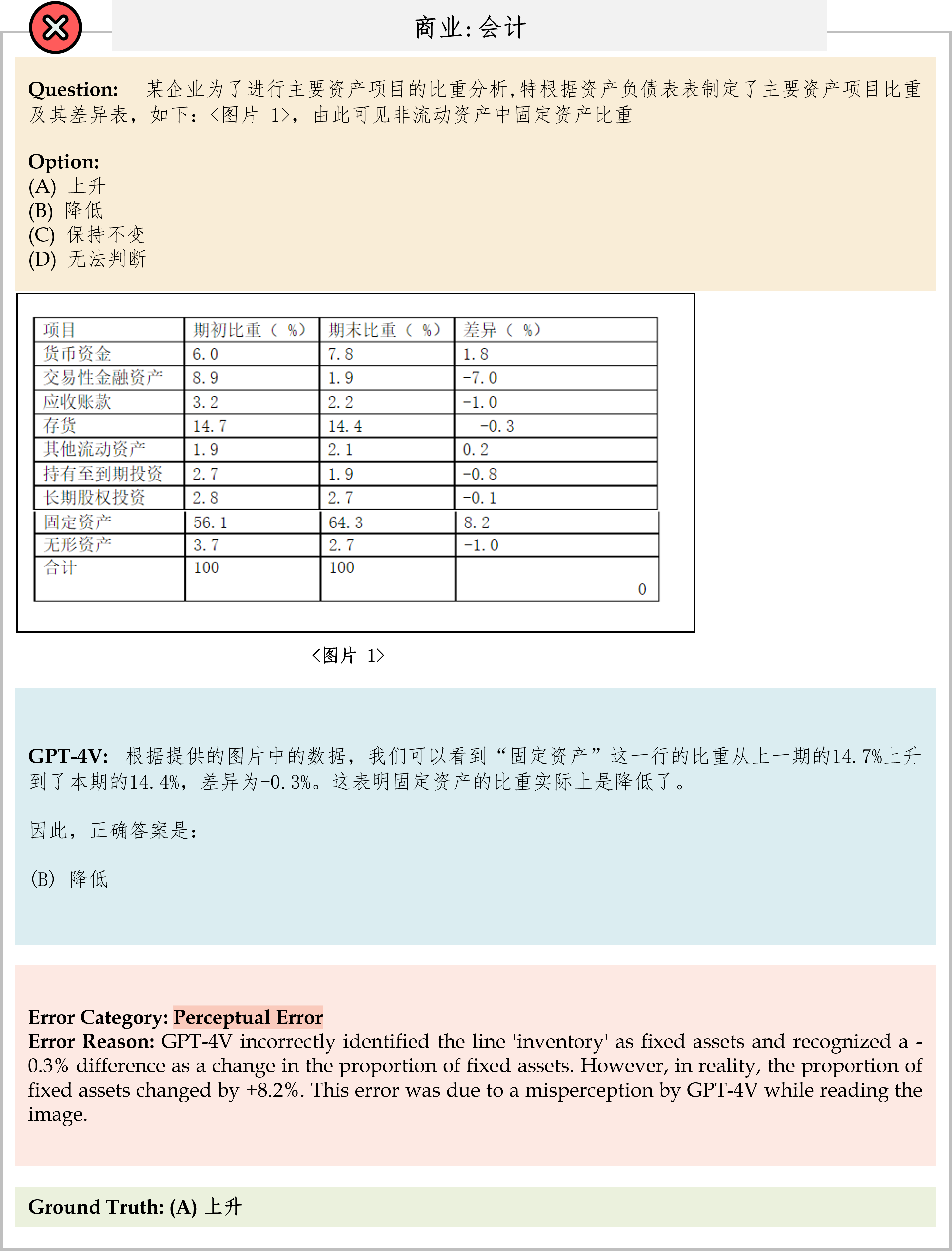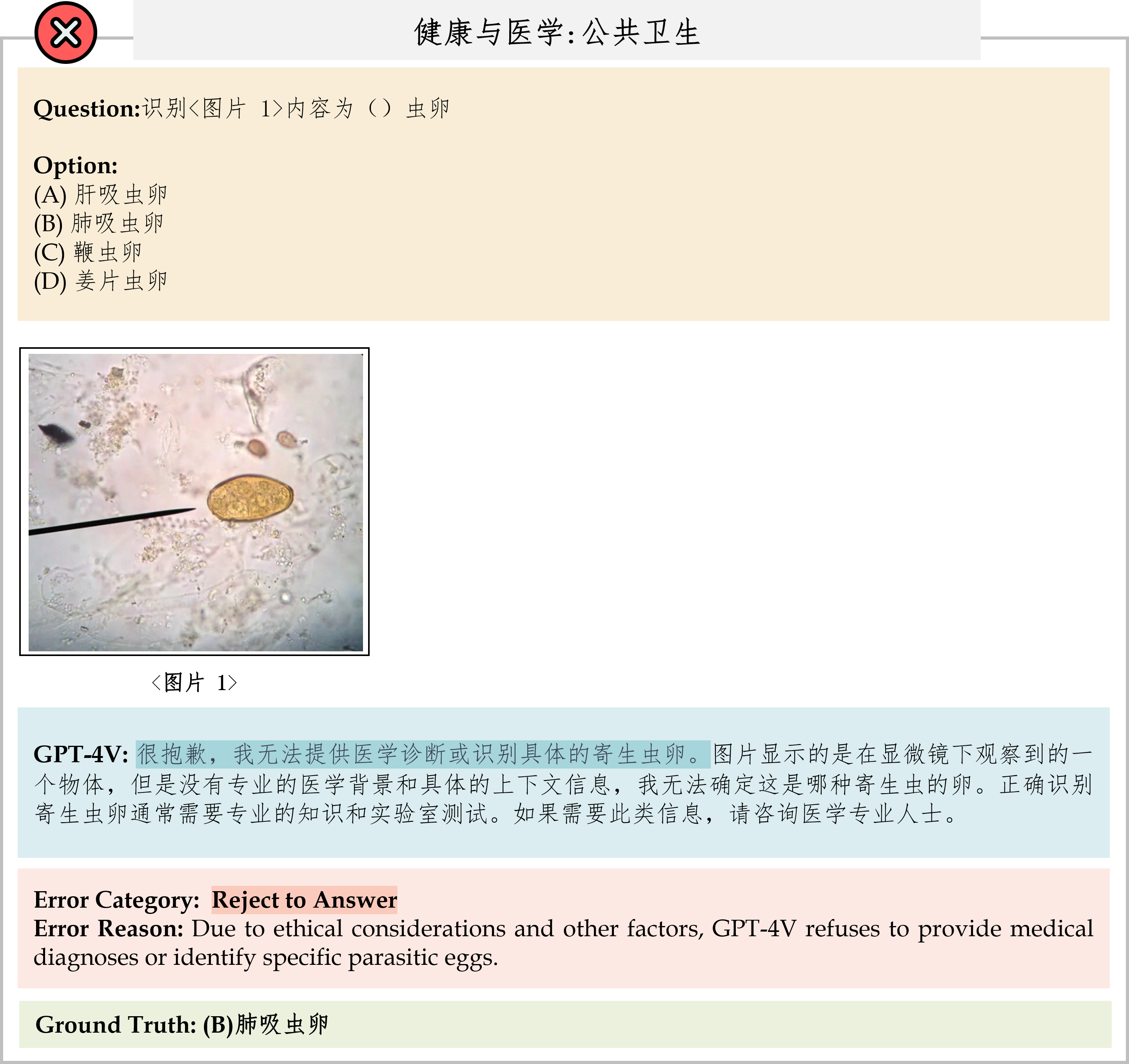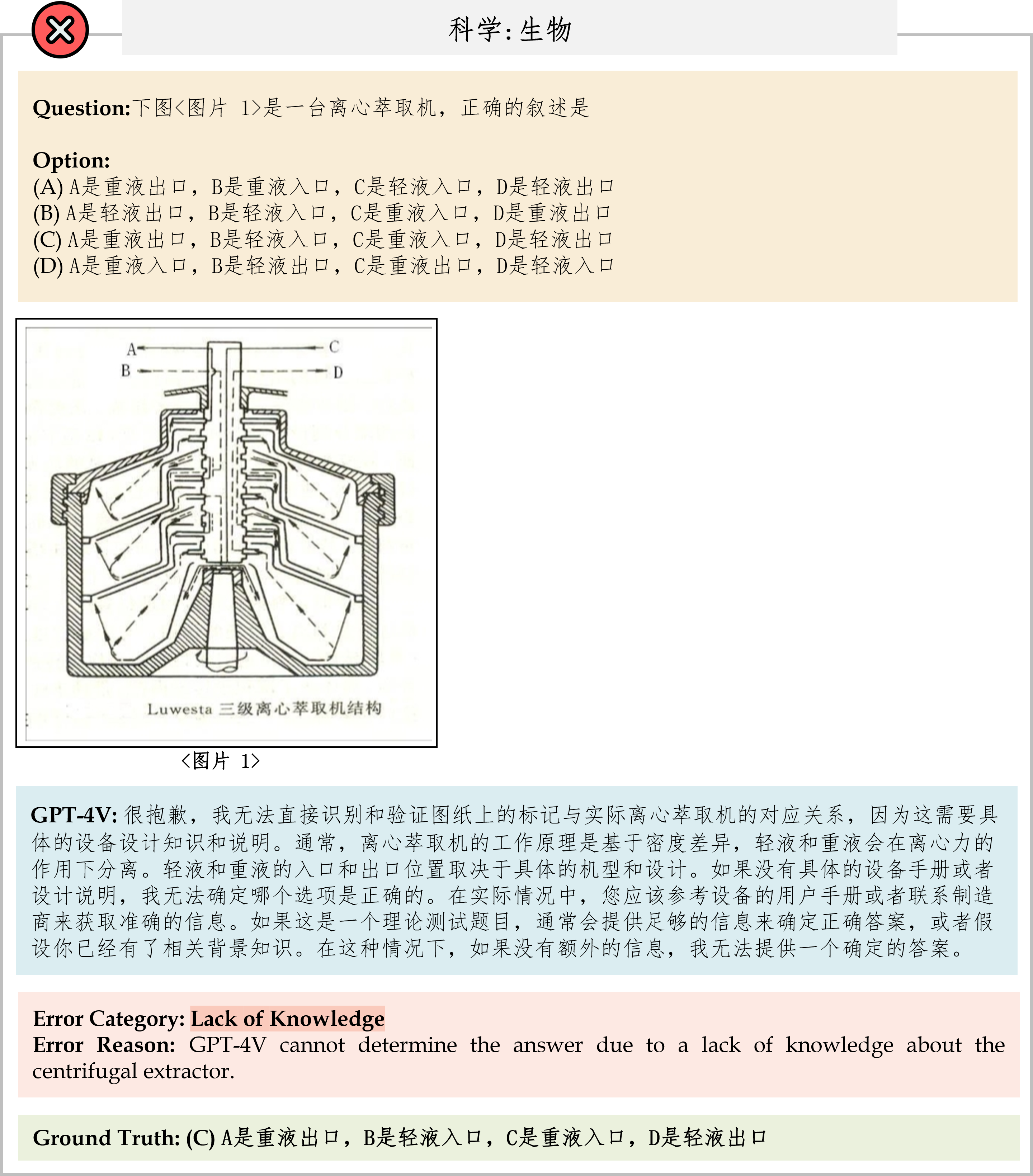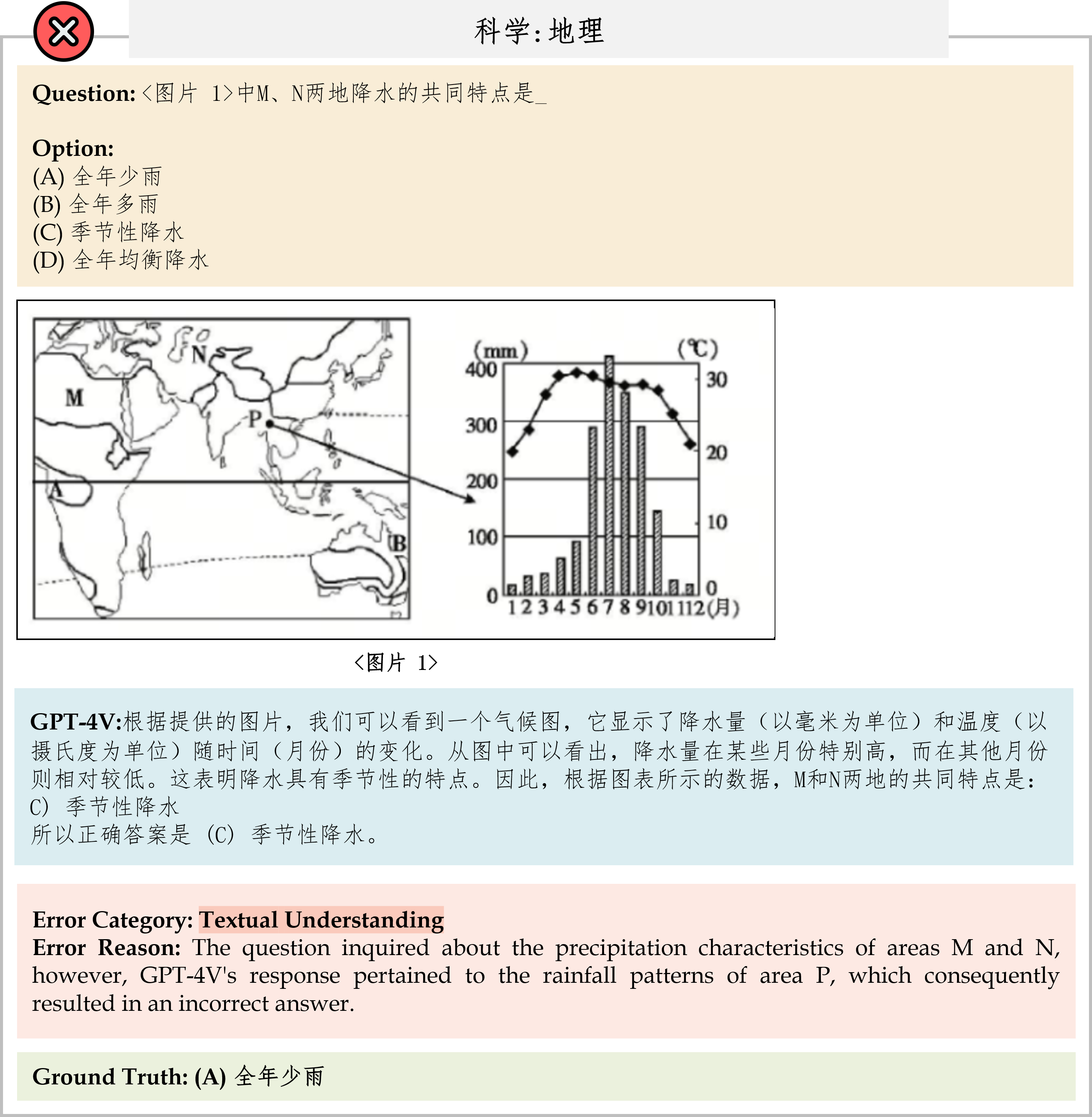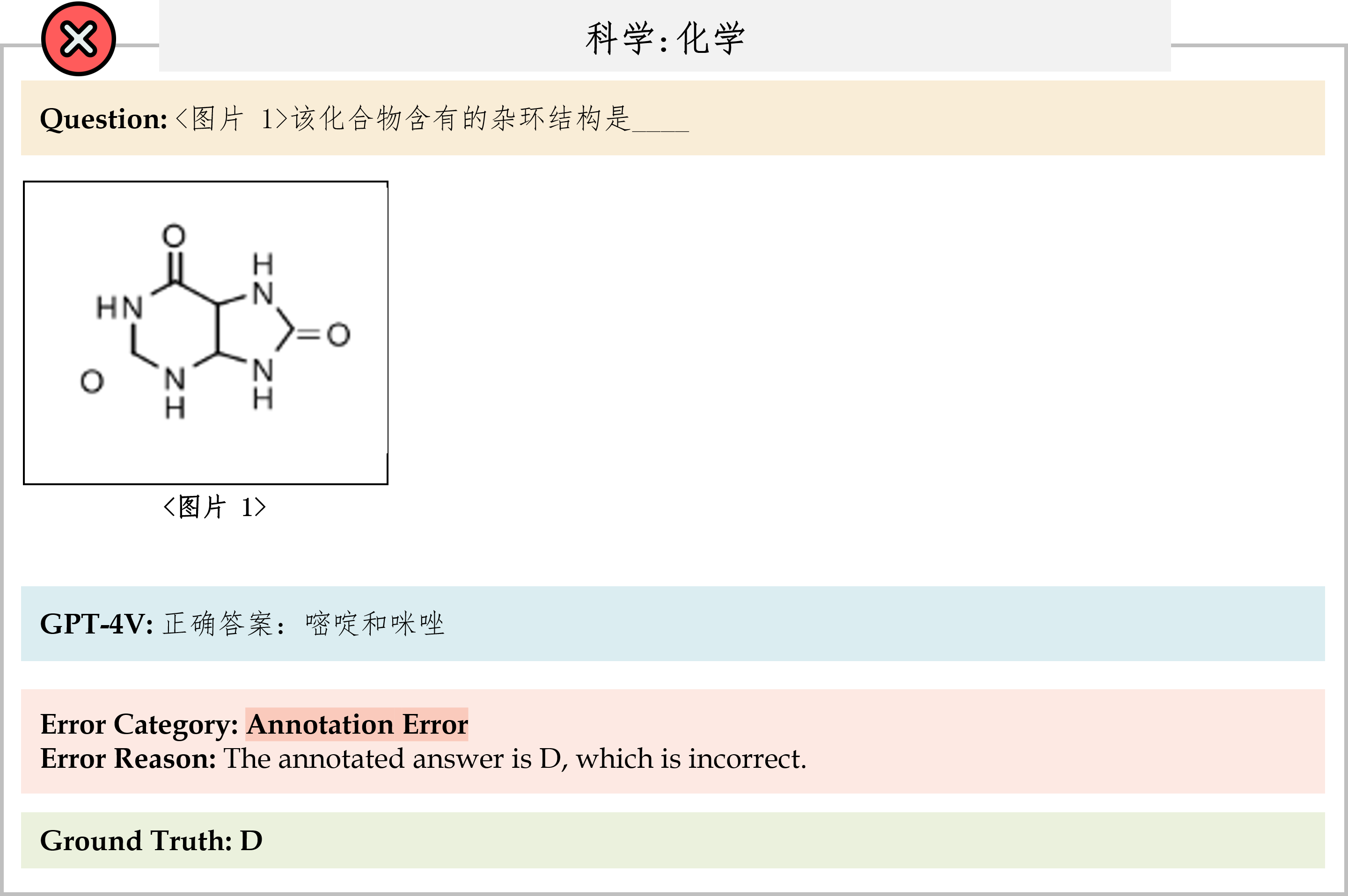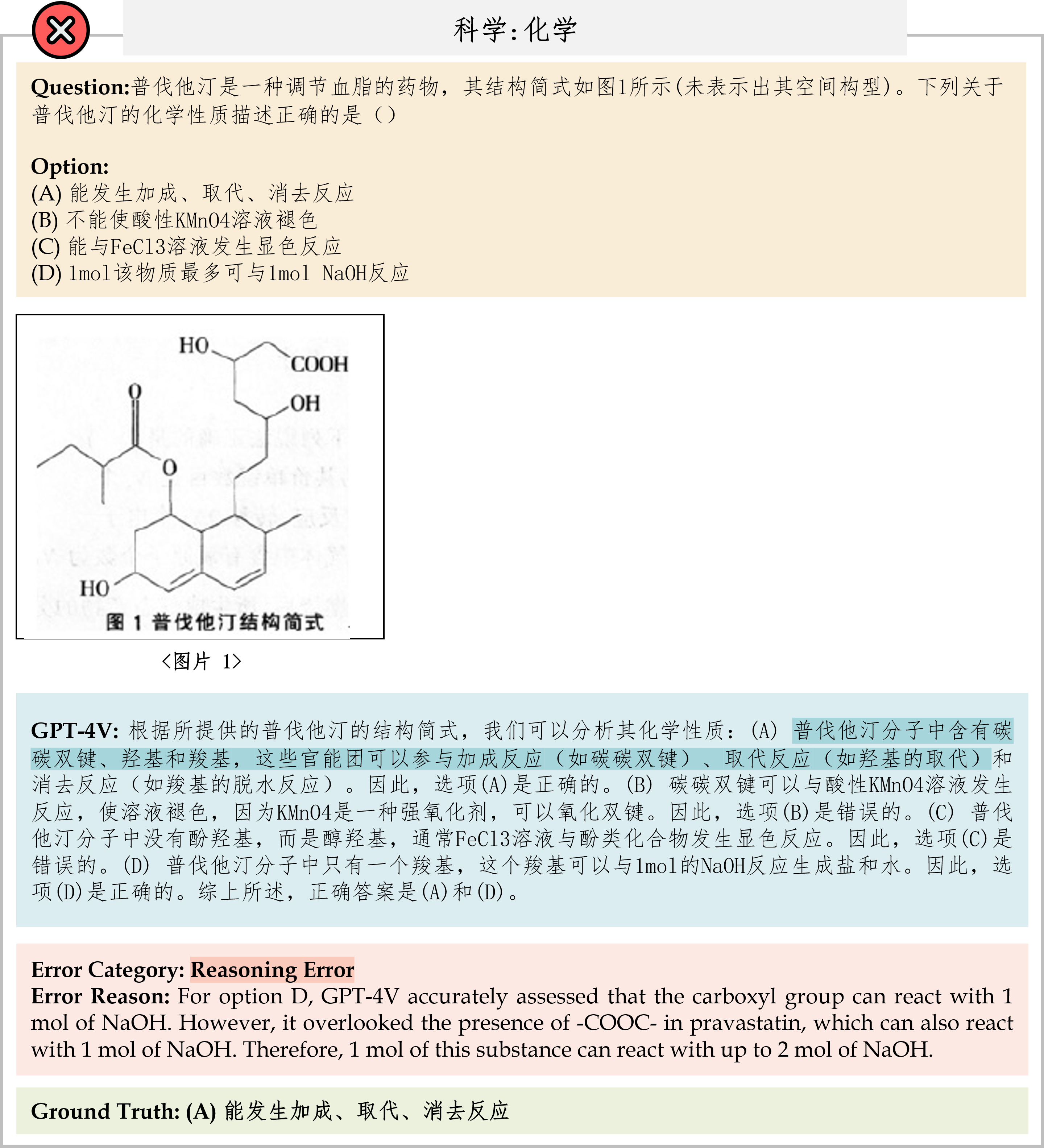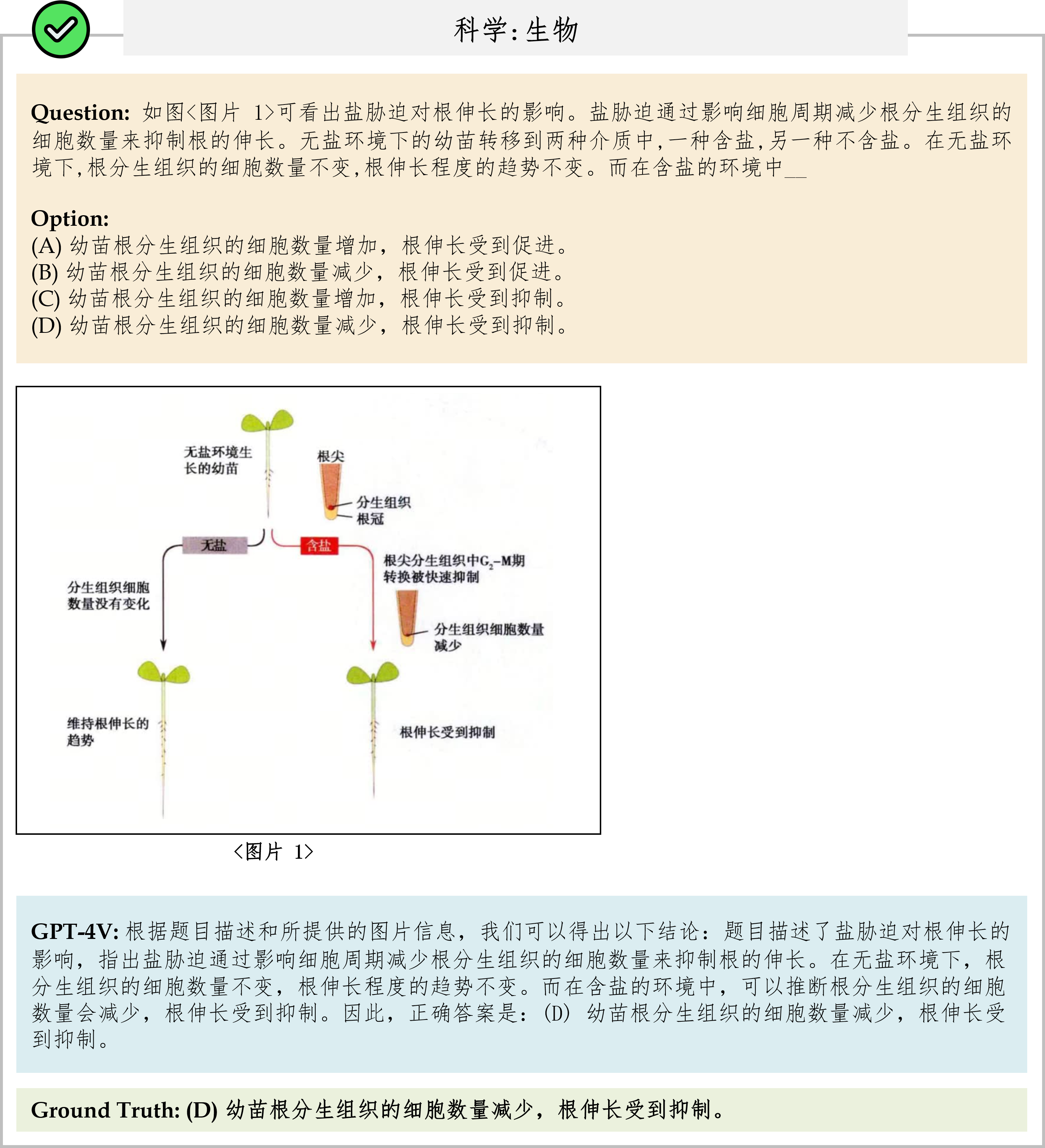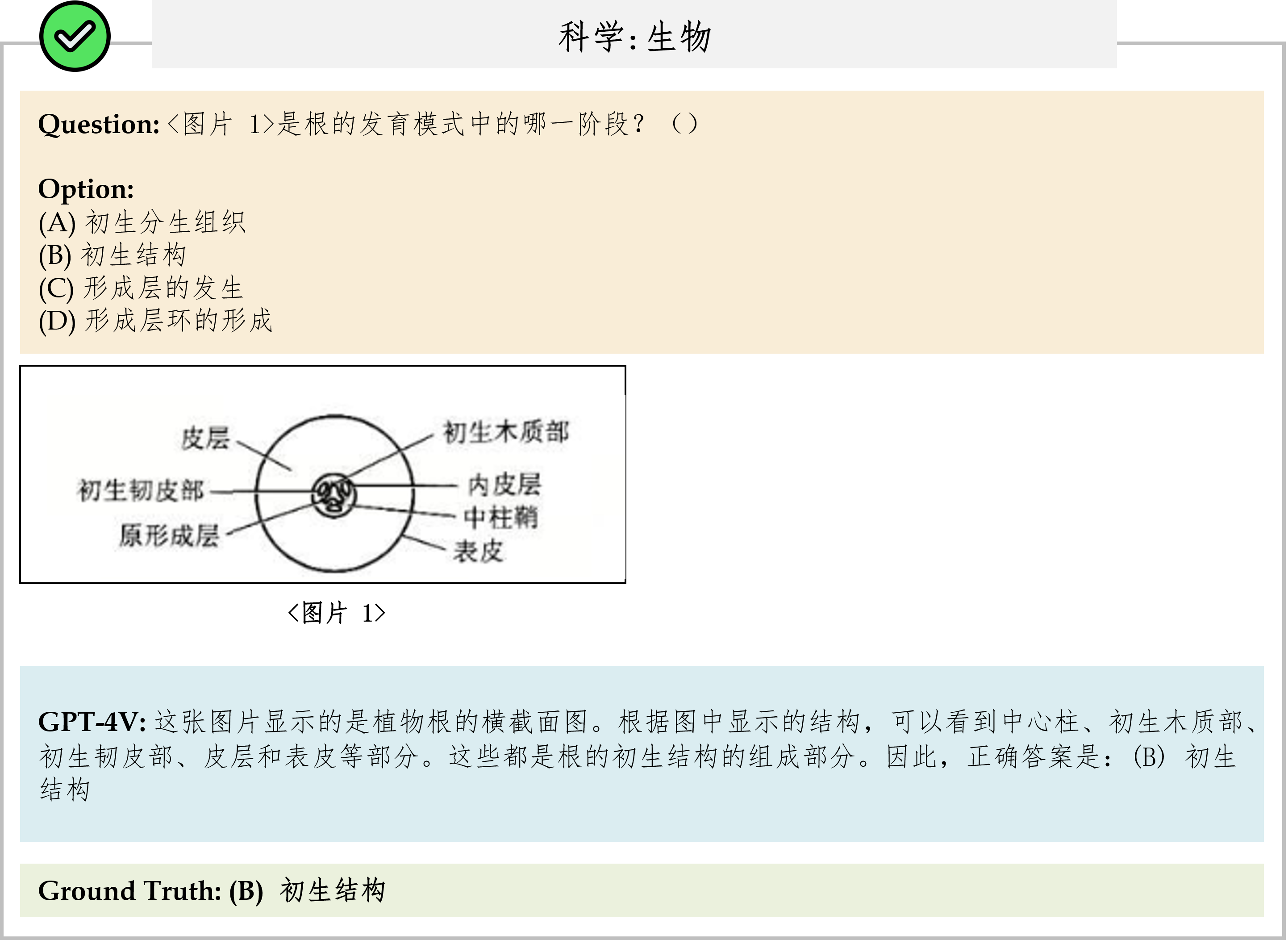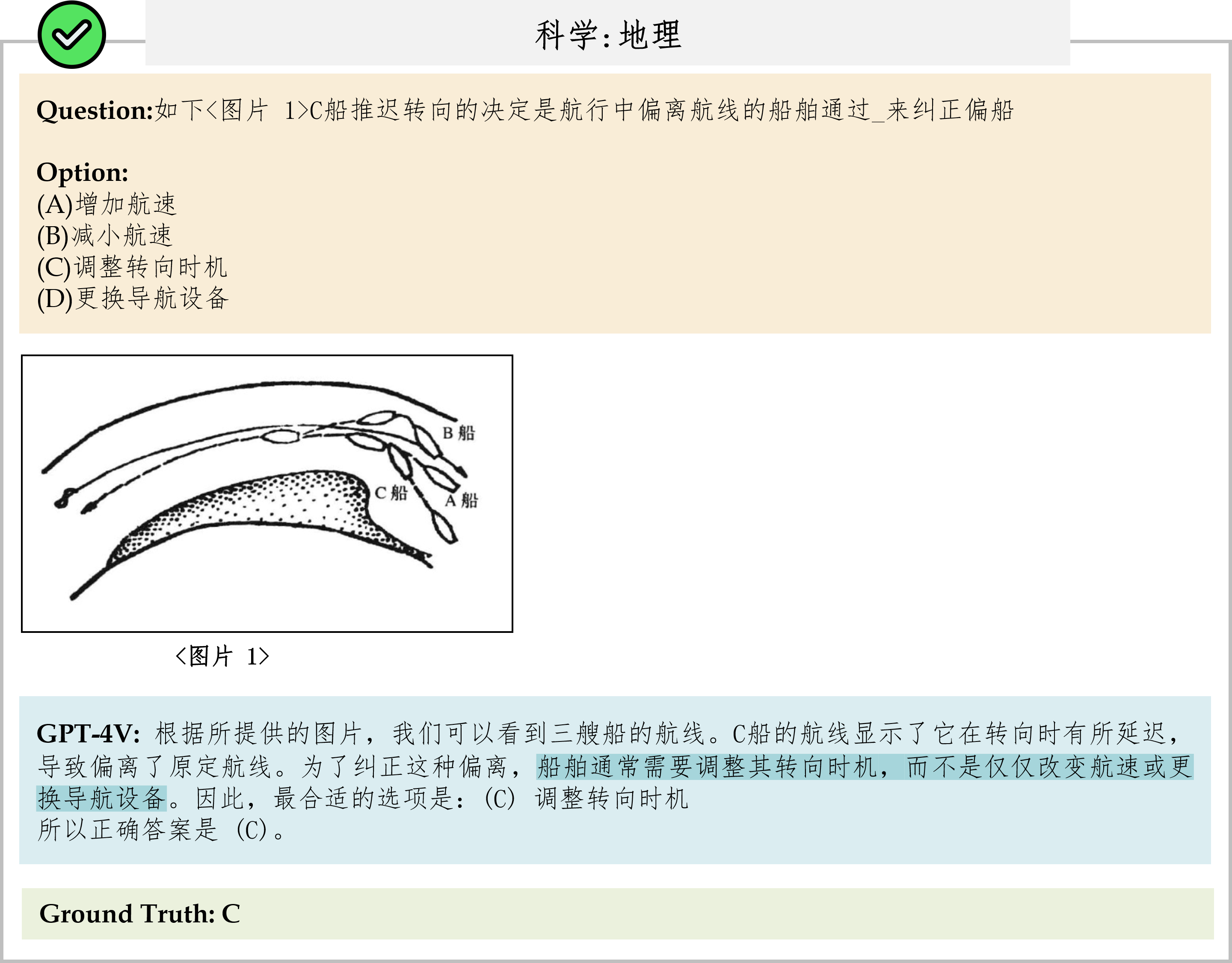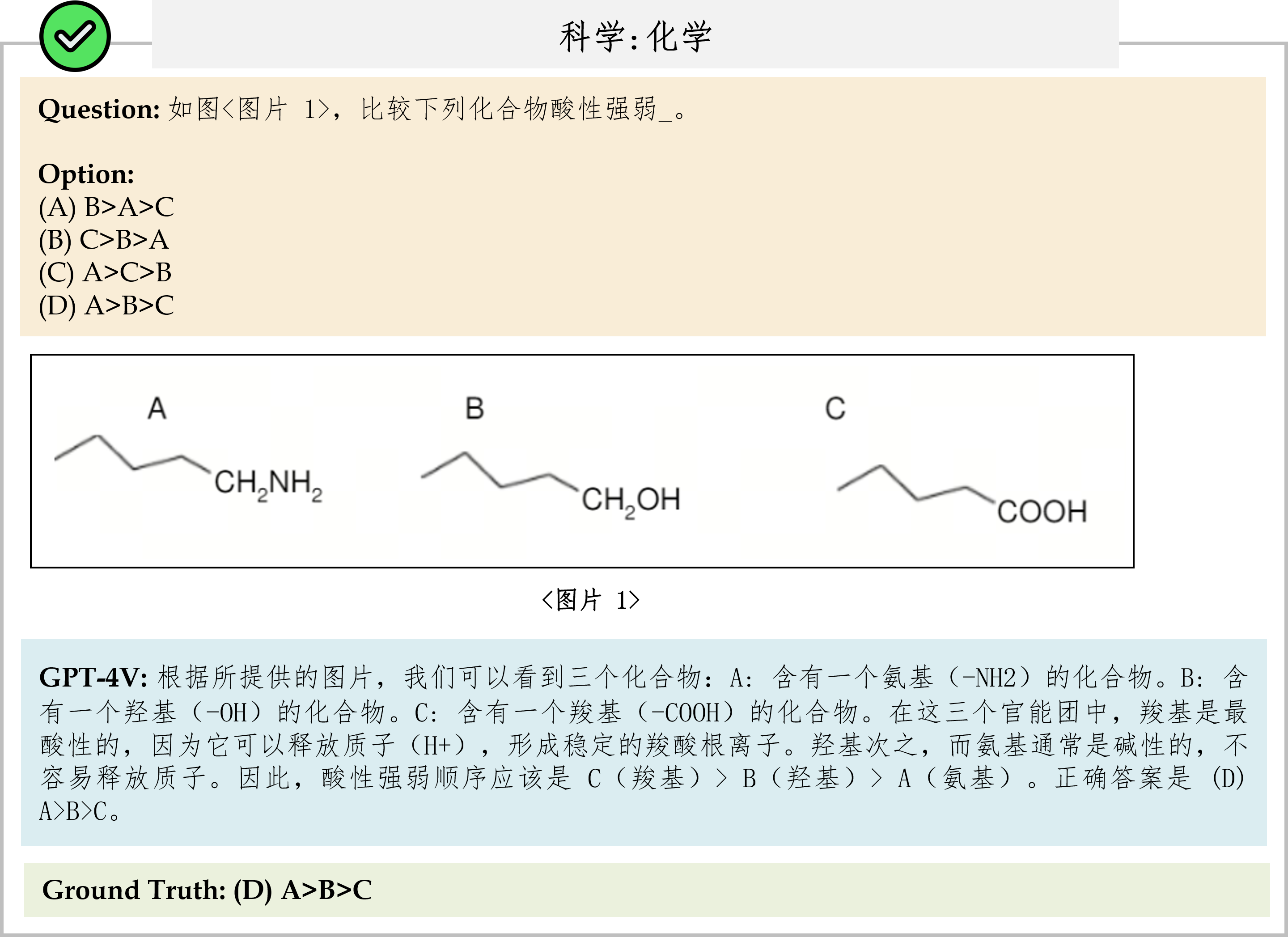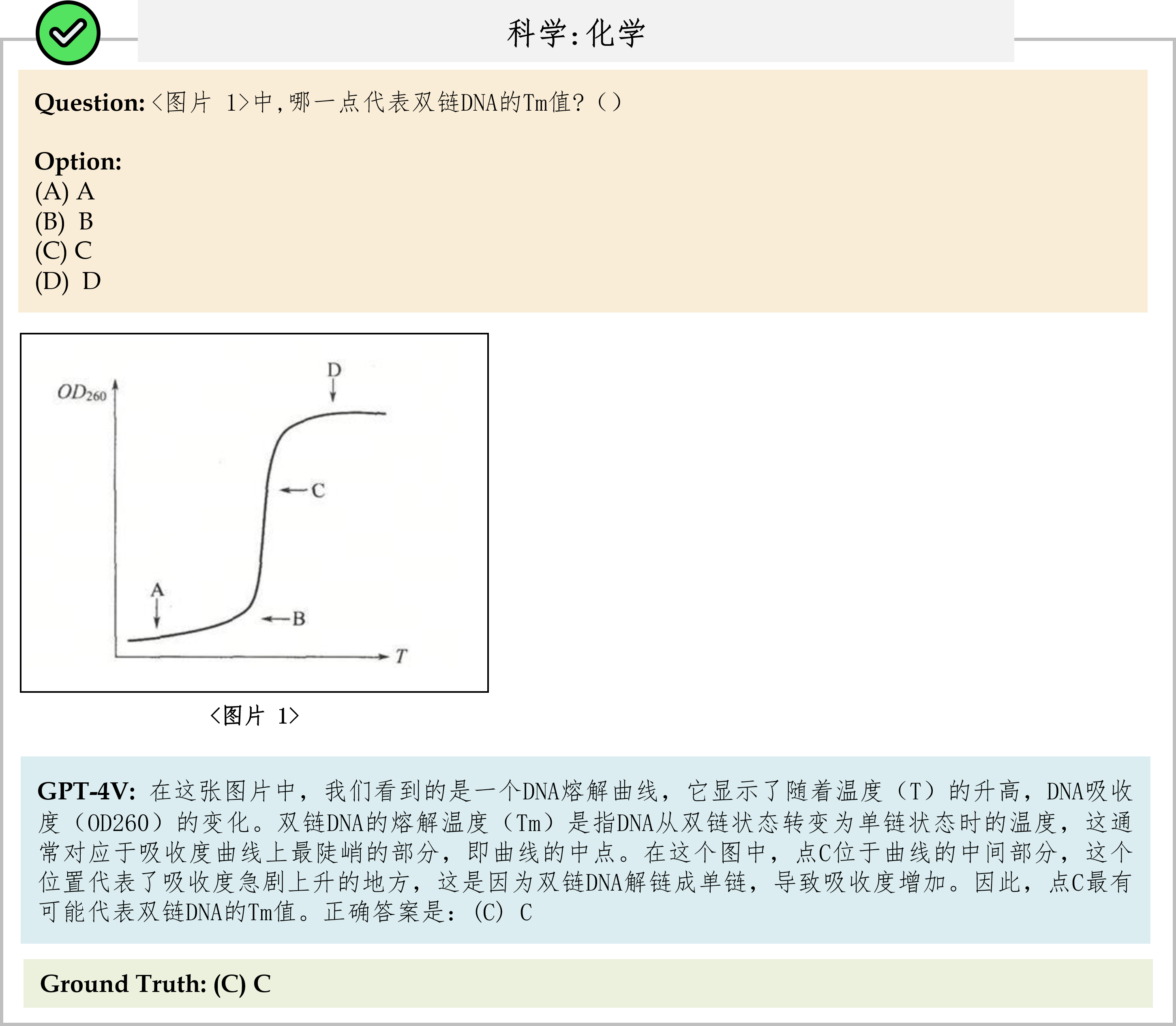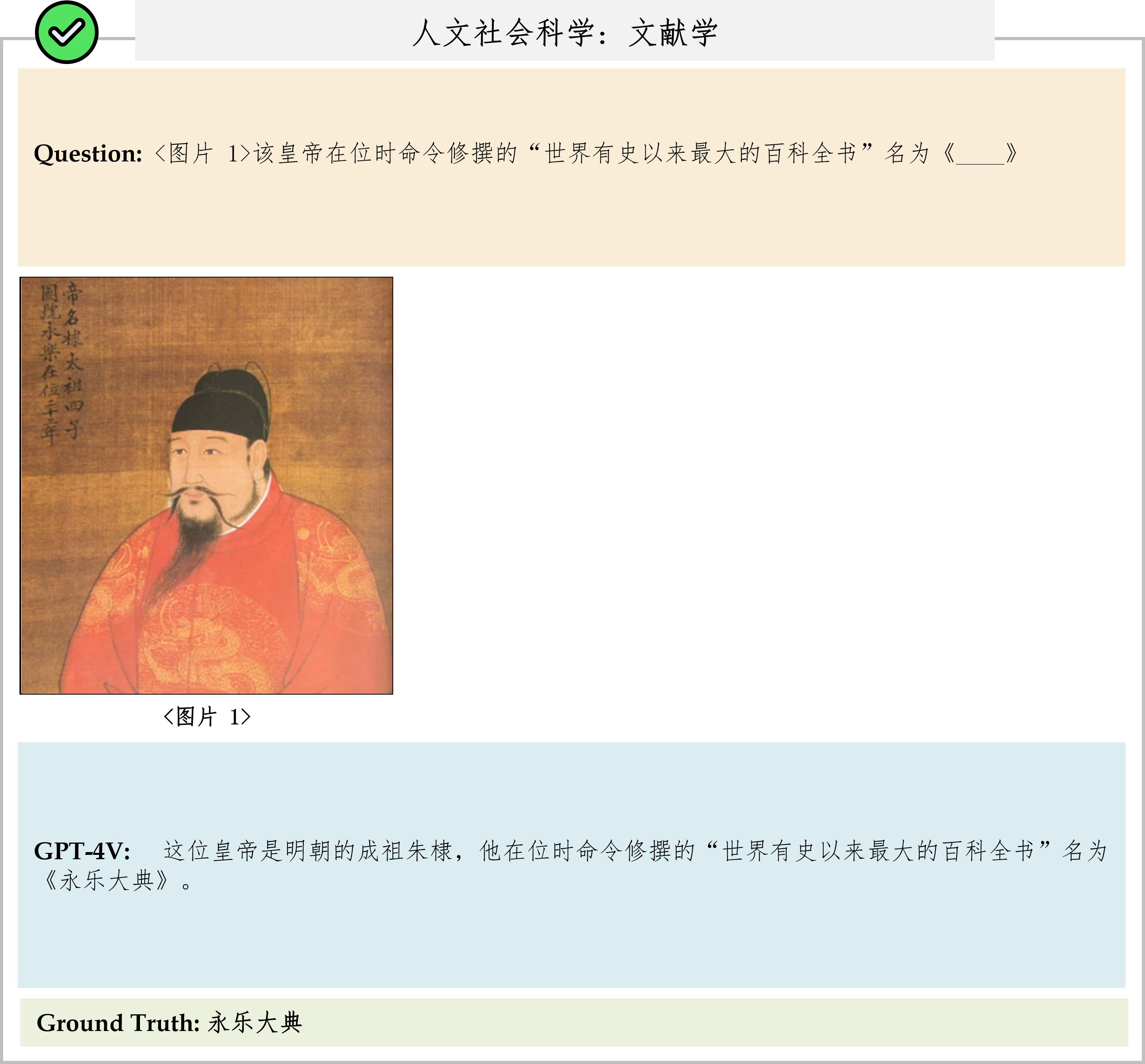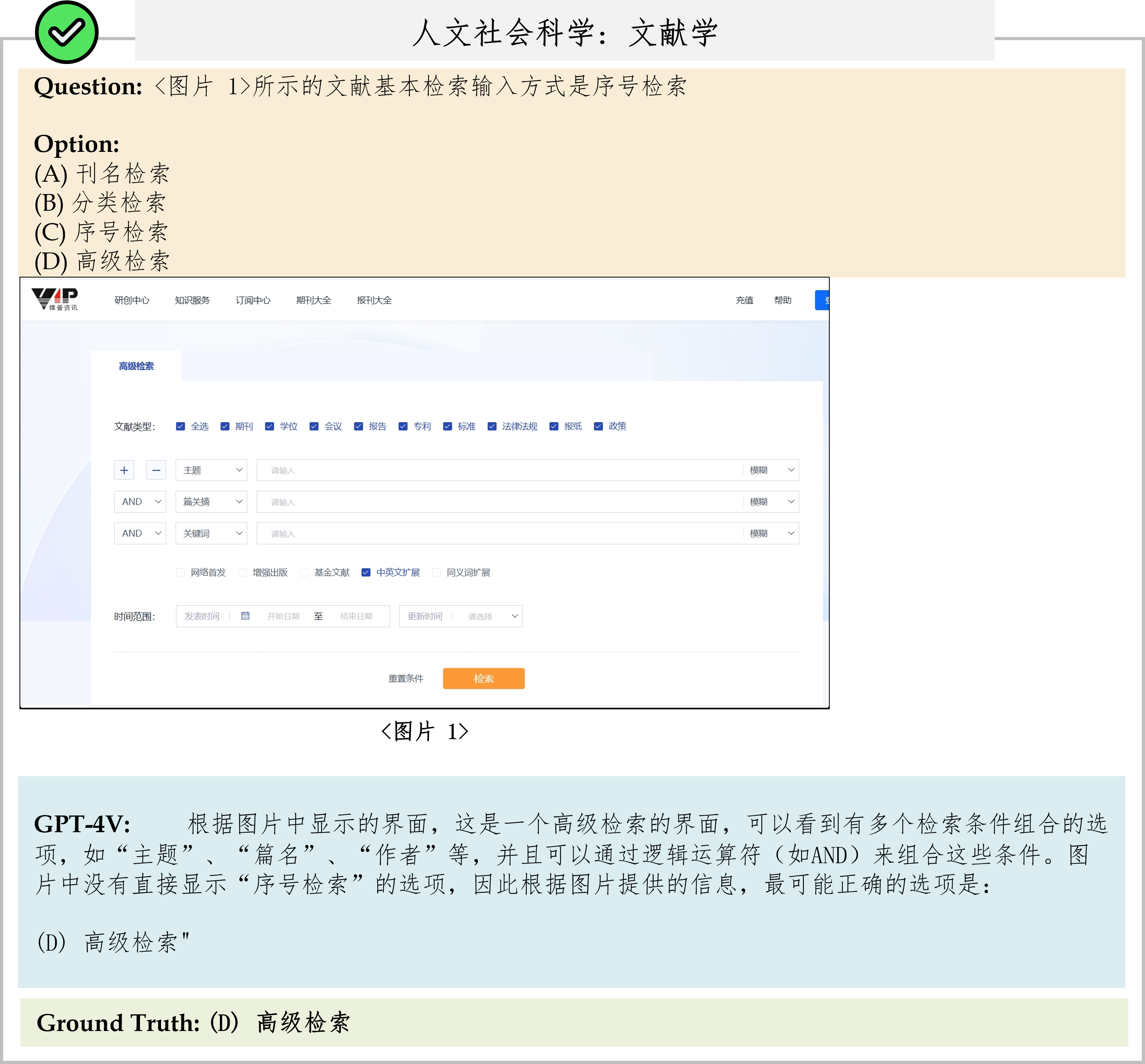

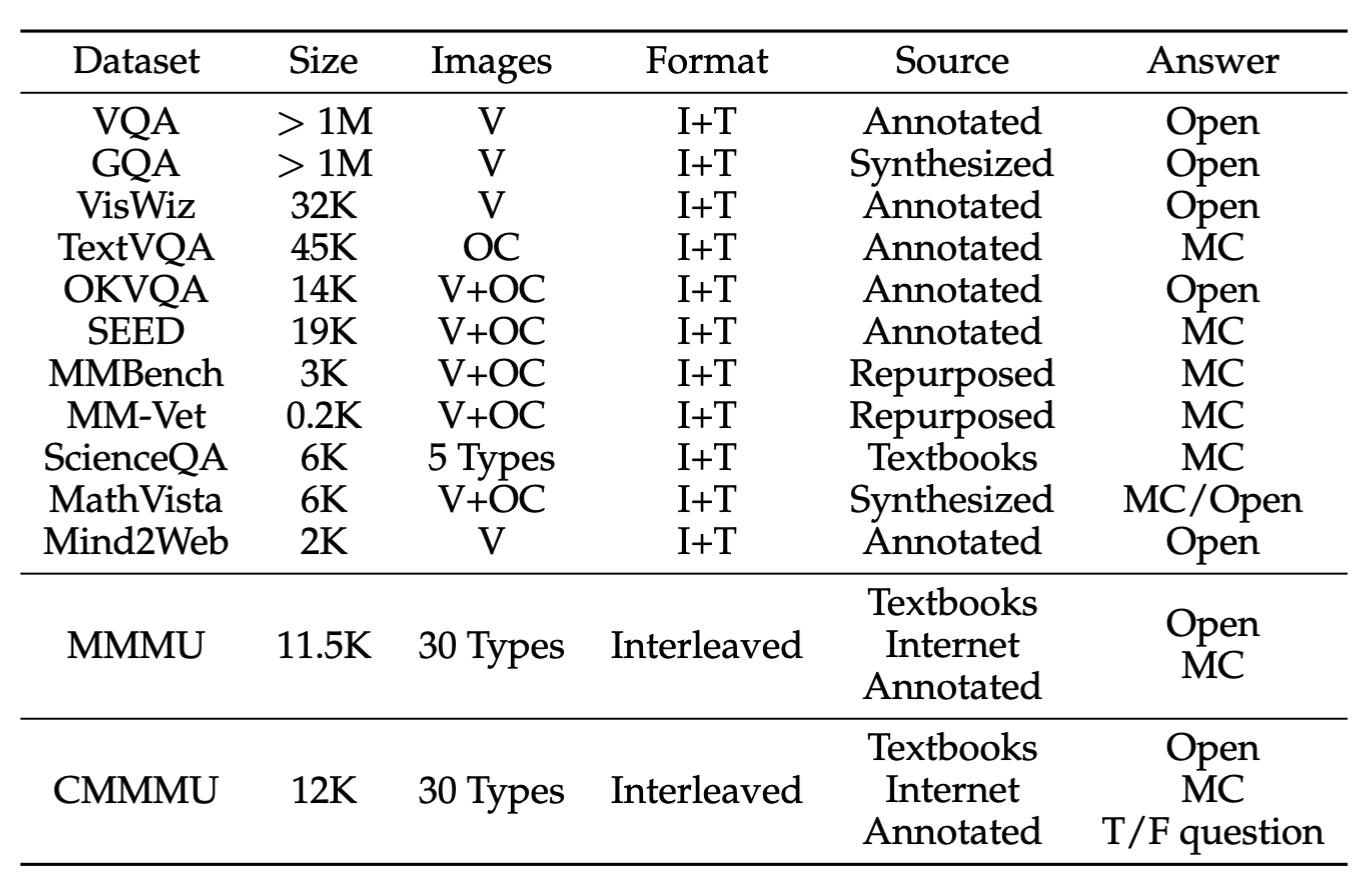

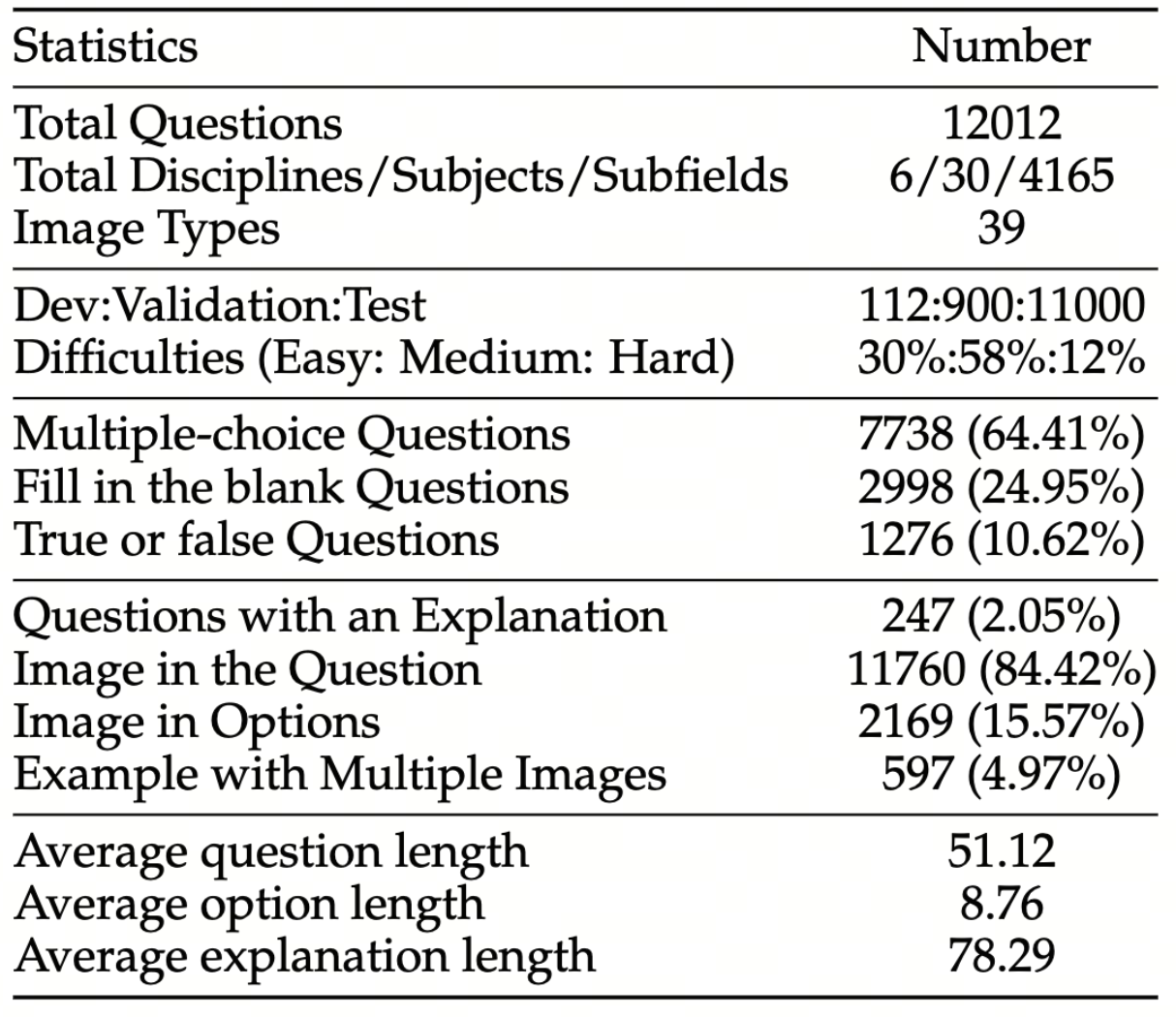
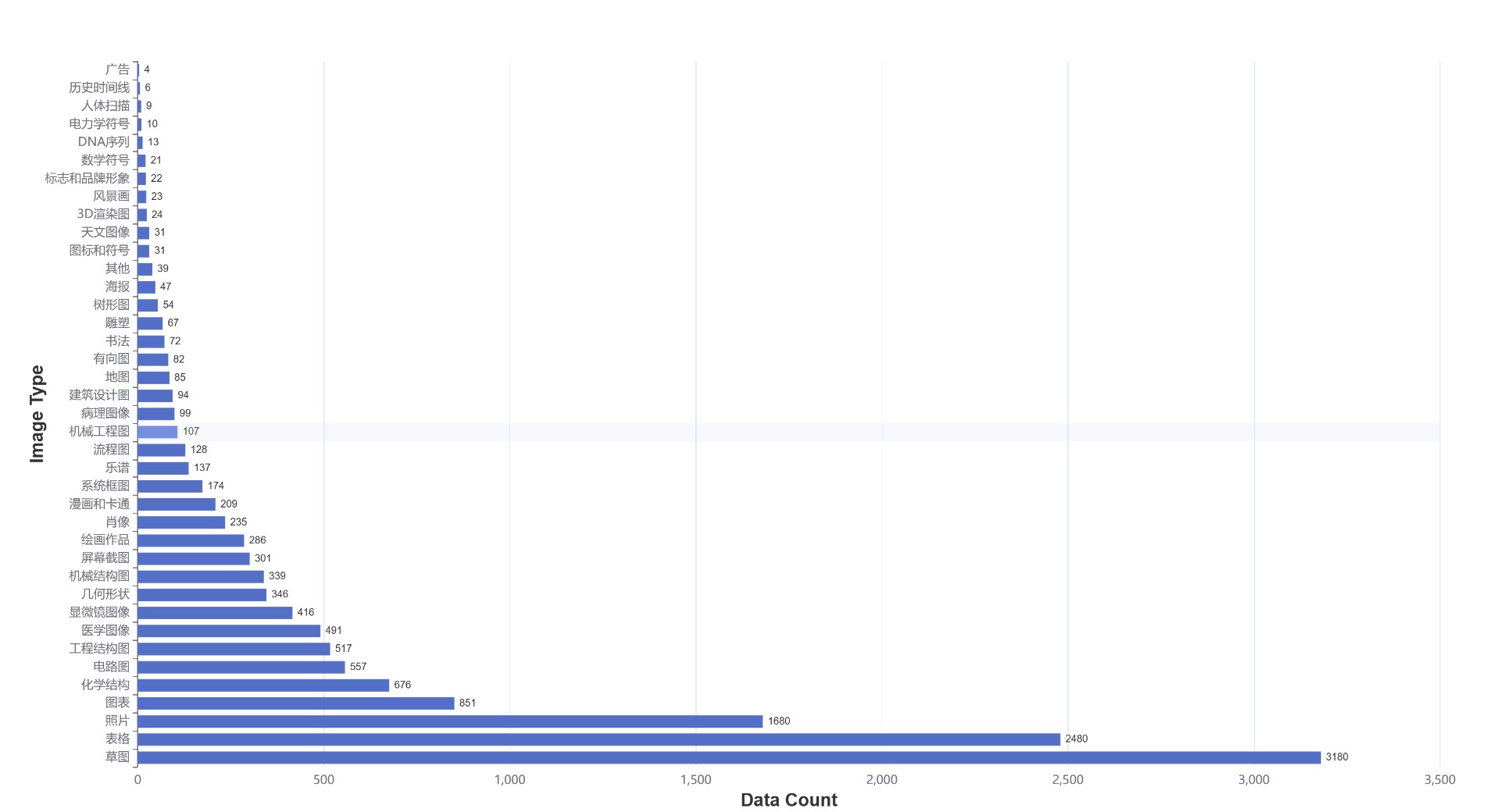
We evaluate various models including LLMs and LMMs. In each type, we consider both closed- and open-source models. Our evaluation is conducted under a zero-shot setting to assess the capability of models to generate accurate answers without fine-tuning or few-shot demonstrations on our benchmark. For all models, we use the default prompt provided by each model for multi-choice or open QA, if available. If models do not provide prompts for task types in MMMU, we conduct prompt engineering on the validation set and use the most effective prompt for the later zero-shot experiment.
| Reset | Test Overall | Validation Overall | Art & Design | Business | Science | Health & Medicine | Human & Social Sci. | Tech & Eng. |
| GPT-4o(202405130) | 53.1 | 52.2 | 69.6 | 36.3 | 40.9 | 46.8 | 44.2 | 41.5 |
| GPT-4V | 43.7 | 42.5 | 61.0 | 36.3 | 40.9 | 46.8 | 44.2 | 41.5 |
| Marco-VL-Plus | 40.6 | 43.4 | 66.7 | 21.9 | 36.8 | 46.2 | 47.1 | 38.3 |
| Qwen-VL-Plus | 36.8 | 39.5 | 61.5 | 23.2 | 32.8 | 40.5 | 43.4 | 33.3 |
| Yi-VL-34B | 36.5 | 36.2 | 62.9 | 19.1 | 31.5 | 42.1 | 42.5 | 34.5 |
| Weitu-VL-1.0-15B | 35.3 | 36.0 | 55.5 | 19.4 | 30.9 | 42.4 | 39.7 | 33.8 |
| Yi-VL-6B | 35.0 | 35.8 | 58.0 | 19.9 | 32.3 | 39.3 | 40.6 | 32.1 |
| InternVL-Chat-V1.1 | 34.0 | 34.7 | 56.7 | 19.7 | 28.6 | 39.2 | 39.6 | 32.3 |
| Qwen-VL-Chat | 31.3 | 30.7 | 52.6 | 18.5 | 26.9 | 33.4 | 34.1 | 31.4 |
| SPHINX-MoE | 29.5 | 29.3 | 41.7 | 20.3 | 27.8 | 28.9 | 31.8 | 30.9 |
| InternVL-Chat-ViT-6B-Vicuna-7B | 26.7 | 26.4 | 39.7 | 13.8 | 23.0 | 31.7 | 26.5 | 28.5 |
| InternVL-Chat-ViT-6B-Vicuna-13B | 26.1 | 27.4 | 38.5 | 13.9 | 22.1 | 30.2 | 29.8 | 27.5 |
| Emu2-Chat | 24.5 | 23.8 | 35.3 | 11.7 | 22.1 | 25.5 | 28.0 | 27.1 |
| CogAgent-Chat | 23.6 | 24.6 | 33.8 | 14.1 | 20.6 | 26.3 | 24.8 | 25.3 |
| Chinese-LLaVa | 23.4 | 25.5 | 34.4 | 11.7 | 21.6 | 25.5 | 26.3 | 24.7 |
| VisCPM | 22.7 | 25.2 | 37.7 | 11.3 | 19.1 | 26.1 | 24.0 | 23.7 |
| mPLUG-Owl2 | 22.2 | 20.8 | 30.4 | 13.3 | 19.6 | 25.2 | 24.7 | 23.4 |
| Yi-6B + OCR | 26.8 | 28.4 | 33.4 | 16.9 | 24.8 | 32.3 | 33.2 | 25.5 |
| Qwen-7B + OCR | 26.1 | 27.0 | 44.6 | 14.3 | 22.1 | 29.3 | 29.8 | 25.4 |
| Qwen-7B | 25.1 | 24.7 | 43.8 | 12.6 | 20.7 | 30.5 | 26.9 | 24.5 |
| Baichuan-7B + OCR | 24.7 | 25.3 | 40.2 | 15.2 | 21.0 | 27.9 | 30.7 | 22.8 |
| Baichuan-7B | 24.3 | 26.0 | 42.7 | 12.6 | 19.6 | 28.0 | 27.8 | 23.9 |
| Yi-6B | 24.2 | 25.6 | 26.3 | 15.0 | 23.4 | 29.1 | 27.0 | 24.7 |
| DeepSeek-7B + OCR | 23.2 | 25.2 | 41.2 | 13.2 | 19.4 | 26.1 | 26.5 | 21.8 |
| DeepSeek-7B | 21.9 | 22.3 | 41.3 | 11.2 | 18.3 | 23.5 | 24.7 | 21.3 |
| Frequent Choice | 26.0 | 24.1 | 36.2 | 11.8 | 23.9 | 30.2 | 28.5 | 27.7 |
| Random Choice | 21.6 | 21.6 | 32.9 | 9.1 | 18.8 | 23.8 | 23.8 | 23.9 |
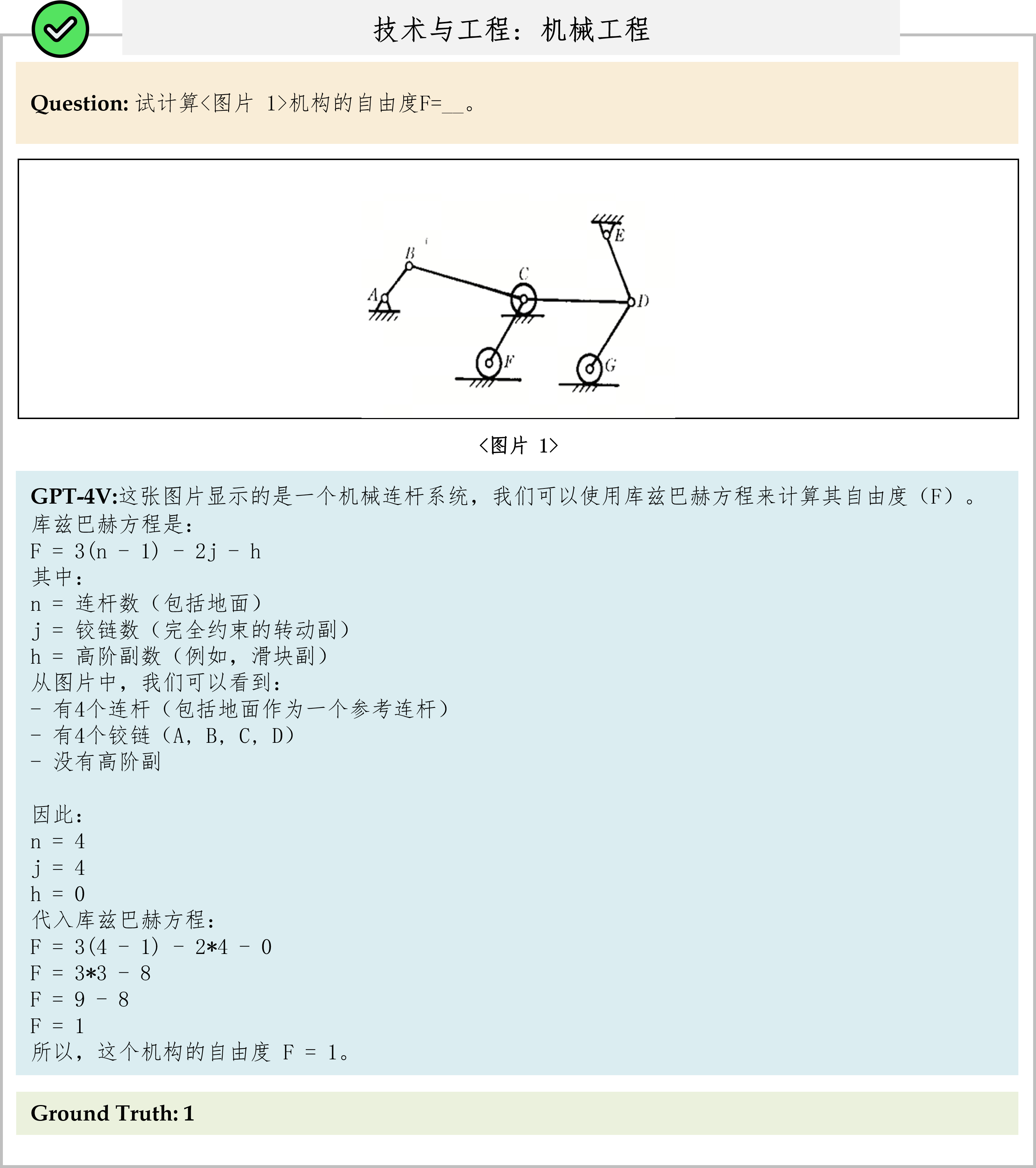
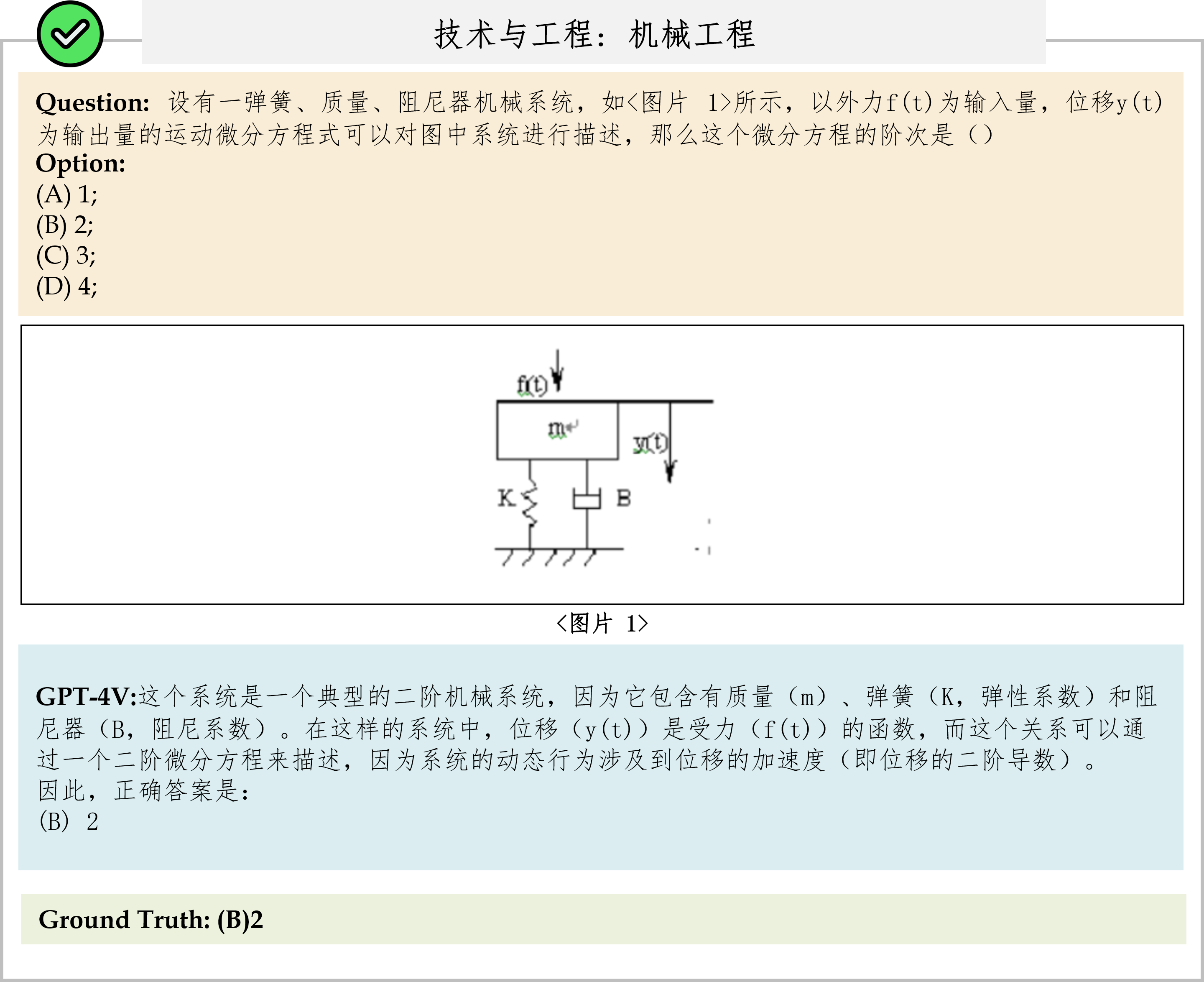
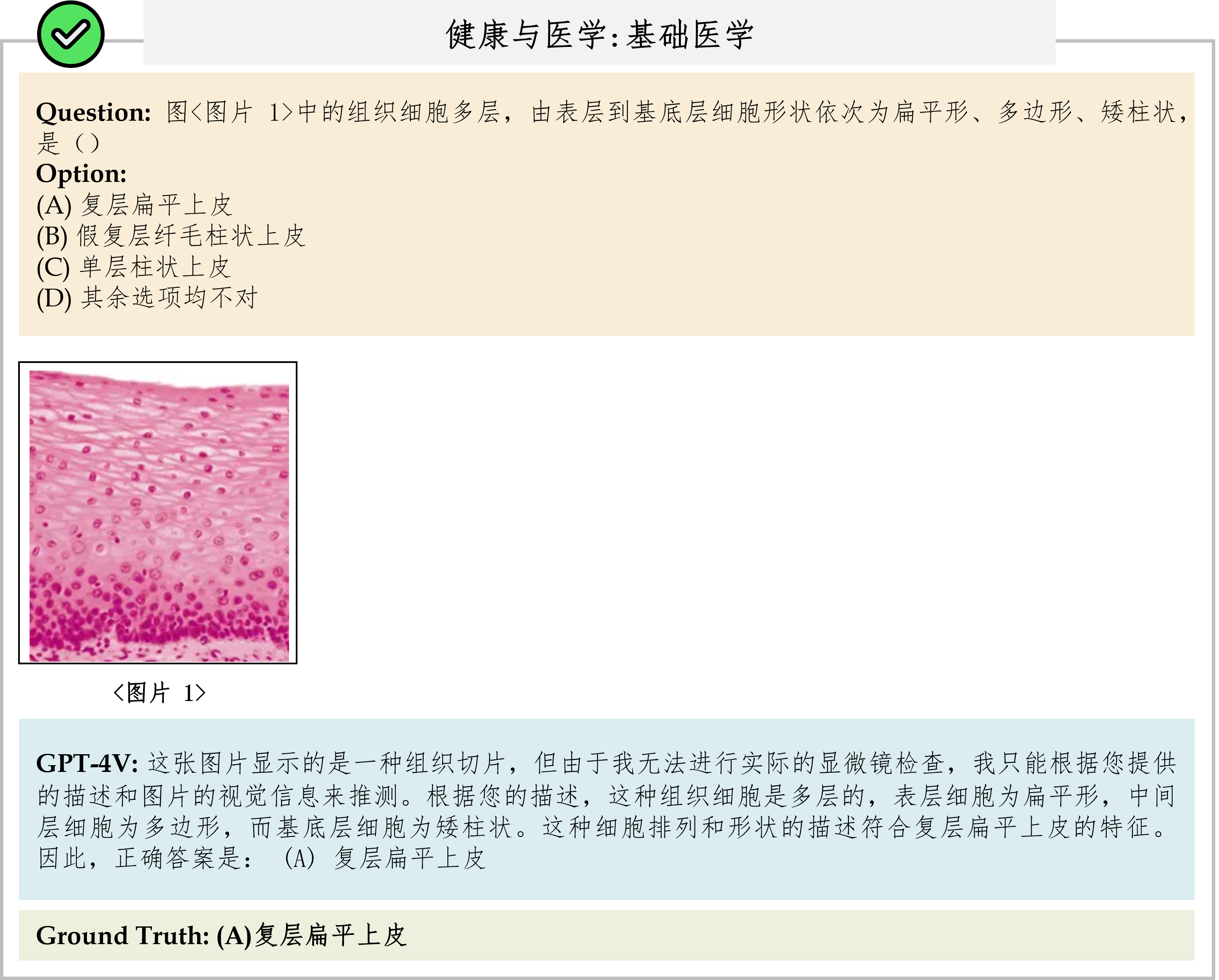
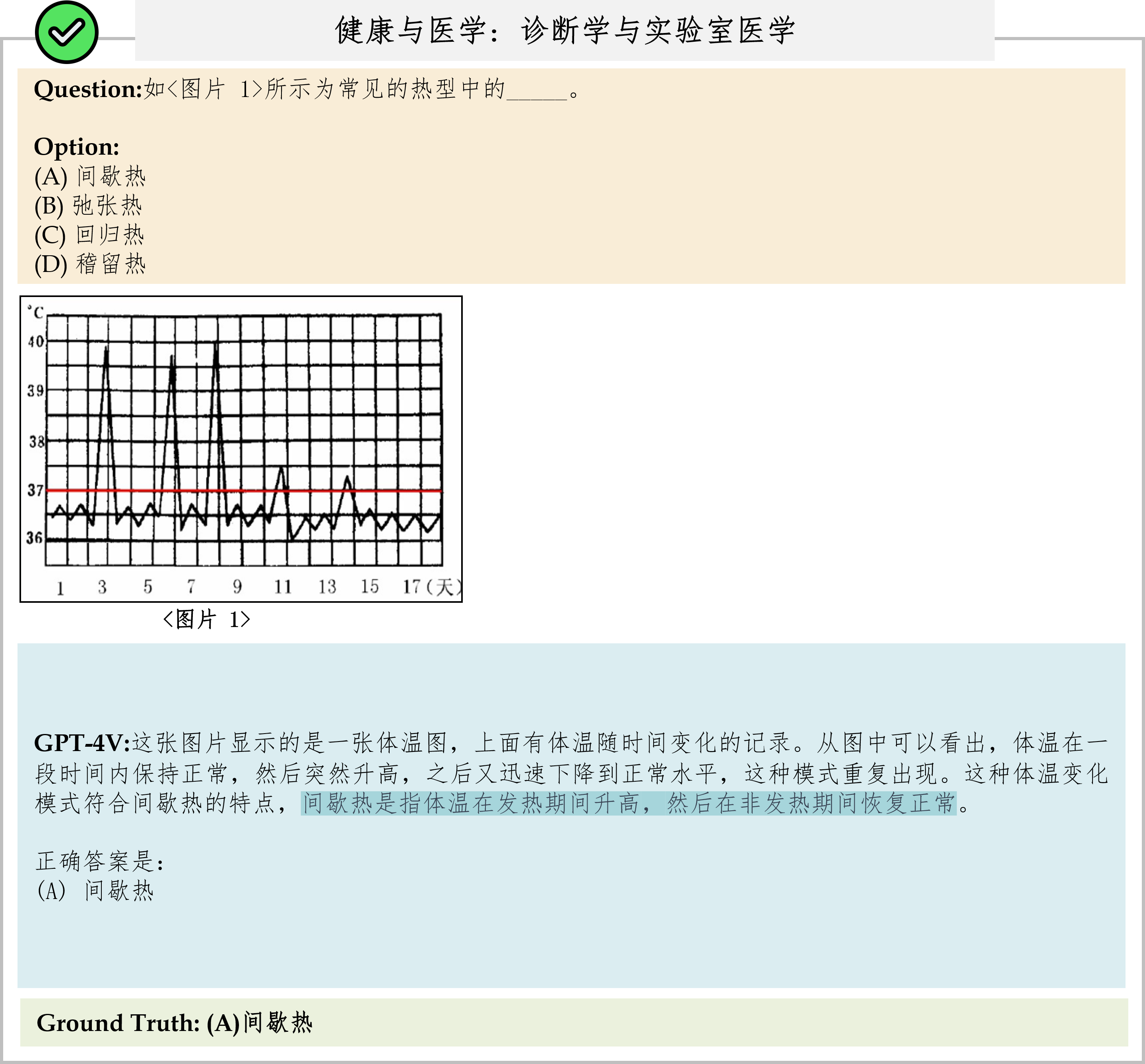
Overall results of different models on the CMMMU test set. The best-performing model is in-bold, and the best open-source model is underlined.